In Part I, we looked at the problem we want attackers of UOV to solve. In Part II we had plenty of oil and vinegar, but did not really discussed the whole unbalanced part of the scheme. So in this third part of this three part series, I will discuss why we are using Unbalanced Oil and Vinegar in particular, and discuss the Kipnis–Shamir attack on the original Oil and Vinegar scheme.
The paper that presented this attack is formulated in the language of matrices, but in my opinion, and showing my biases as a algebraic geometer, one can’t fully understand the problem when in this language, and I will instead present it in the language of bilinear forms, that I have build over the last two blog posts. Using bilinear forms is useful, since it allows us to present things without having to chose an explicit basis, which means that we do not really have to distinguish between the public and the private key all that much.
Preliminaries
Most of this section is a mini course in linear algebra and in particular bilinear forms and dual vector spaces. I will try to also formulate the attack purely in terms of matrices, so if this is going too far for you, you might still follow along with the attack, but as mentioned, using the language of bilinear forms in my opinion gives a deeper understanding.
First, as a quick refresher, as discussed in Part II, a UOV public key is a set of bilinear forms , which have the property that there exists a subspace such that for all . This subspace is the private key we are looking for. The attack in question is a key recovery attack working with the public key only, so we don’t really need to repeat how signing works, and we will focus solely on how to recover this subspace given the bilinear forms, with Part II discussing the signature scheme.
We also need some additional vocabulary to talk about bilinear forms. Bilinear forms in positive characteristic behave somewhat weirdly sometimes, so it makes sense to prove stuff from scratch anyways.
First, we need to discuss non-degenerate bilinear forms. A bilinear form is called non-degenerate, if, for all vectors there is at least one vector such that . If you look at the matrix defining the bilinear form, this is equivalent of saying that this matrix has full rank.
The reason we care about non-degenerate bilinear forms is because they allow us, on a finite dimensional vector space at least, to “transpose” vectors, i.e. turn column vectors into row vectors. If you know quantum physics, what a non-degenerate bilinear form does is turn a ket vector into a bra vector. If you don’t know quantum physics, don’t worry about it, those are just terms the quantum physicists invented because they didn’t know enough about bilinear forms and dual vector spaces.
To understand dual vector spaces, all you need to know here is that linear forms, i.e. linear functions that output a single scalar, themselves also form a vector space over the same field, since you can add linear forms and multiply them with scalars. Conceptually, these are literally just row vectors, as mentioned above, since those can be multiplied with column vectors to give elements of the base field, i.e. row vectors define all the linear forms that exists (for a finite dimensional vector space. Infinite dimensional vector spaces are very, very different, and to take back my comment on quantum physicists a bit, those are what quantum physics deals with, but still, understanding dual vector spaces would make their field a whole lot more approachable). We write for this dual vector space.
To tie this to our bilinear forms, the important thing a bilinear form allows you to do is to “curry”, or partially evaluate it, that is given a bilinear form and an element , we can look at the linear form .
And for non-degenerate forms, doing this partial evaluation gives you an extra property, namely that, if , we know that as well, since the linear form 0 is defined by being 0 for all vectors in the vector space, and linearity in the first argument means that , so by definition of non-degeneracy it follows that . What this means is that, if is linear independent, then is linear independent as well. This proves the statement I made above of finite dimensional vector spaces having the same dimension as their dual, and means that every non-degenerate bilinear form gives us a way of mapping column vectors to row vectors. This might seem like a lot of work for literally just turning a page 90 degrees, but as I said, quantum physicists still pay the price for thinking they could turn papers better all by themselves.
Next, we need to talk about orthogonality. This term really only makes geometric sense in characteristic 0, but we can still use it algebraically: Two vectors are called orthogonal if . For a subvectorspace we define . With this definition, we can rephrase the trapdoor of our bilinear forms as there being a subspace such that . Basically, a subspace that is perpendicular to itself in all bilinear forms of the public key.
While this is somewhat obviously nonsensically in a geometric way, we can rescue at least one property of perpendicularity into positive characteristic, and that is the dimension of the orthogonal space:
For a non-degenerate bilinear form , and a subvectorspace , we have . To see this, take a basis of . For every basis vector , we again look at the linear form . This gives us many linearly independent linear forms, all of which vanishing on . We can consider these forms as a linear function , and since they are linear independent, we know that this linear function has full rank. Vanishing on all forms makes the kernel of this function, and by the kernel-rank theorem, this implies that .
The Attack
With all of this out of the way, we can now look at the attack itself. So in the following, we have bilinear forms , defined over an -dimensional vector space with , i.e. there are as many oil vectors as there are vinegar vectors, and everything is “balanced”. We also have a secret, -dimensional sub vector space such that for all , as discussed above. One thing to note here is that , so in this balanced case, and only in this balanced case, we further get , since a subvectorspace that has the same dimension as the space is equal to the space.
The main idea behind the Kipnis–Shamir attack is that bilinear forms are hard, but linear functions are easy, and that for two non-degenerate bilinear forms and there is exactly one linear function such that for all . We know this, because both and are non-degenerate, so both can map a basis of to a basis of the dual vector space , so is the map given by this base change. More concretely, if is represented by the matrix , i.e. , then , as a linear function, is represented by , since . If we hadn’t done all this work about bilinear forms, we would now need to add a two line proof that this is invariant under base change. I instead opted for writing several paragraphs worth of linear algebra, which, as surely we will all agree, is far preferable.
So far, so unremarkable. You have a bunch of bilinear forms, you can define this linear function. But now, we can ask what is. We know that for any vector , for all vectors , so we know that as well, so we know that . But as pointed out above, in the balanced case , so . This means that (technically, I have not proven equality, but that follows pretty easily by applying non-degeneracy again). This means , restricted to the subvector space is an endomorphism.
But for a linear function, restricting to a subvectorspace as an endomorphism is the same as saying that this subvectorspace is a product of eigenspaces. And we can compute the eigenspaces of a linear function. By itself that is only moderately helpful, since we don’t know which eigenspaces of are part of and which aren’t. But we don’t just have one , we have a linear function for every pair of bilinear forms. And we can intersect eigenspaces, and find the common eigenspace of multiple linear functions. Two random linear functions are very unlikely to share an eigenspace, and we have linear functions sharing an eigenspace. So that common eigenspace is just . I describe how to compute that shared eigenspace below, but see the paper for more details.
To put it together, the attack algorithm works as follows:
Discard all singular matrices, as they correspond to degenerate bilinear forms.
Compute for enough .
Take an arbitrary linear combination of the computed matrices
Compute the characteristic polynomial of and factorize it.
Due to the common eigenspace, the characteristic polynomial will always have a factor of degree m. But it might have more factors. If there are more factors, discard and try a new linear combination. If you do not find such a matrix and factorization, continue at step 7.
By Cayley–Hamilton, the kernel of factor of the characteristic polynomial, evaluated at the matrix, is the eigenspace of the matrix. Since our matrix has a characteristic polynomial which only has two factors, one of the two eigenspaces is the oil space, which we can quickly verify.
Read the paper for why finding such a characteristic polynomial is very likely, so you never reach this step.
A geometric interpretation
I have to admit, when I first read about this attack, I found it extremely devastating. A polynomial time attack on one member of a family of schemes is a very frightening thing to see, and while the attack clearly requires n = 2m to work (Otherwise the whole eigenspace argument falls apart), at least I would like to see some form of an argument why n > 2m somehow is not just mitigating this specific attack, but also fundamentally has a structure that is somehow more complex than the balanced case is.
I think I have found such an argument, but as a fair word of warning, what follows will be some take no prisoners, deep, deep end of the algebraic geometric pool. Well the shallow end of the deep end, but you get my drift. I will try to keep the argument understandable for more general audiences, but you’ll have to take a bunch of things I say at face value. The whole argument is part of a deeper investigation I did on UOV, but that should properly be a different blog post, or maybe a CFAIL paper or something like that.
With the disclaimers out of the way, here we go:
If an algebraic geometer is given m polynomials, even if they are just quadratic forms, our basic instincts kicks in, and we study the geometric object obtained by setting all these polynomials to zero. I will call this the oil-and-vinegar variety, i.e. . Note that even though these polynomials are homogenous, we need to keep our animalisticgeometric urges in check and not look at for now. This variety is a subvariety of , and since it is given by m polynomials, it, assuming the polynomials are complete intersection, will be dimensional. For the non-geometers: This is similar how having m linear equations creates an n – m dimensional vector space, with “complete intersection” being the equivalent to things being linearly independent, only that stuff can go wrong in a lot more interesting ways, and in general stuff bends a lot more, but importantly, if you take random polynomials, they are very likely to be complete intersection, so if our oil and vinegar polynomials were not, that in itself would be remarkable. It’s unfortunately not really possible to check whether polynomials are complete intersection without computing Gröbner bases, see part I, but when I tried it the tiny cases I could compute Gröbner bases for, things were complete intersection up until n = 2m (for n < 2m, it cannot be complete intersection as we will see). But I didn’t compute how likely complete intersection is in general.
The other thing to notice is that , seen as a linear subvariety of , is a subvariety of , since the quadratic forms, by definition, evaluate to 0 on . And is m dimensional. This shows that for n < 2m, cannot be defined by polynomials in complete intersection, since it’s dimension m is greater than n – m.
So in the balanced case, where n = 2m, is a m dimensional algebraic variety, with an m dimensional linear subvariety. In other words, an irreducible component of . The Kipnis–Shamir attack isolates this linear component from the other, nonlinear components of .
Artist’s impression of the OV-variety for m = 1, n = 2. You can see the linear subspace as irreducible component. Note that this is a polynomial of degree 3, so it is not actually a valid OV-variety, but it would look boring otherwise.
In the unbalanced case however, n > 2m, so . Which makes a closed subvariety with codimension greater than 0, i.e. lies on some, itself non-linear, irreducible component of . It does at least conceptually make sense to me that there might be an algorithm to tease out a linear irreducible component, but that linear closed subvarieties of non-linear components are much harder to pry away.
Plot of a m = 1, n = 3 OV-variety. There are plenty of linear subspaces to chose from (which would not usually be the case), but they are all located on a single irreducible component which is decisively non-linear. It’s still not the greatest picture, since the plotting software limits me to three dimensions only.
After Part I looked at the hard problem underlying Unbalanced Oil and Vinegar, it is now finally time to talk about the algorithm itself.
Verify
As with many signature algorithms, looking at the verification routine first is a good idea. The verification algorithm is usually simpler, and gives you an idea of what the signature scheme is trying to do, with the signing algorithm then showing you how it does it.
In the case of UOV, we use a paradigm called “hash and sign”, in many ways the simplest signing scheme paradigm, not using any fancy transforms. All we need is a trapdoor one-way function , i.e. a function that everybody can evaluate efficiently at any point , computing , but where, given , finding an such that is difficult, unless one knowns some extra information , in which case it is easy. In other words, there is a function that is easy to evaluate such that .
Given such a trapdoor one-way function, we can construct a signature scheme by simply making the signature of the (hash of the) message , i.e. the signature of a message is the value such that . The most prominent example of a signature scheme using this paradigm is RSA-PKCS1, where modular exponentiation is the one-way function, and the factorization of the modulus is the trapdoor information making it reversible.
As we discussed in part I, we want to use quadratic forms as our hard problem. At this point, it makes some sense to discuss different ways to write down quadratic forms. They are all interchangeable, and really which one is used is mainly a matter of what is most useful in a given context.
The most straightforward way of writing down a quadratic form is by writing it as a polynomial, i.e. by writing . Note that the second sum starts at , since we are operating over commutative fields, so we can always reorder things so that . This will be useful later. Also note that we only use a homogenous polynomial, i.e. a polynomial without linear or constant components. This is both a simplification and something that does not matter in practice, as you could always homogenize the polynomial.
The second way to notate a quadratic form is using matrix-vector multiplications. If we put our variables into a vector , then will evaluate to the exact same polynomial as above, with being a triangular matrix. We can shift around the coefficients of that are not on the diagonal, as long as remains the same (if the characteristic is not equal to two, which will be a common caveat in this post).
Finally, looking at it makes sense to ask what would happen if we did not use the same vector twice, but instead kept two different ones. This gives us , a bilinear form, i.e. a function that is linear in both arguments and evaluates to a single field element. In other words, given a bilinear form , we get the associated quadratic form by evaluating at the diagonal. Note that for the bilinear form, the order very much matters, since , so in this case, we can no longer simply assume upper triangular matrices. In fact, usually, when studying quadratic forms, mathematicians restrict themselves to symmetric bilinear forms as the associated bilinear forms, i.e. forms with , corresponding to symmetric matrices . This gives a one-to-one correspondence between quadratic forms and bilinear forms, and is super convenient, with the slight downside of not working in characteristic 2. As mentioned, this is a more general thing, having to do with the fact that the degree of the polynomial equals the characteristic, something algebraic geometers call the wild case. And guess which base field UOV uses? That’s right . Super nice for computers, since a single byte corresponds to a field element, but really inconvenient for the more theoretical analysis. We can mostly ignore this, but keep in mind that pretty much everything that uses bilinear forms might have an unwritten asterisk that goes into unreasonable detail about the situation in characteristic 2.
With all this on notation out of the way, we can finally write down the public key and the verification algorithm:
A UOV public key consists of quadratic forms, given as symmetric matrices , of dimension . A signature of a message is a pair , with being an dimensional vector, and some salt, such that .
Written this way, it is clear that the generic way of solving this problem would be equivalent of solving the multivariate quadratic equation problem. Indeed, the signature is literally given by a solution to the multivariate quadratic equation problem defined by public key and message. But keep in mind that just because the problem is formulated as a multivariate quadratic equation, that does not mean that you have to use generic solvers to attack it.
Note that, different from RSA, every message has more than one possible preimage, so even without the salt would allow for multiple signatures. By adding the salt we gain some additional security guarantees, in that it no longer matters whether the signer has signed the exact same message before, since with a different salt it results in a completely different challenge anyways.
Sign
It is now finally time to discuss the trapdoor used for UOV. After all, if our public key was completely random, it would indeed be impossible to forge a signature, but it would be equally impossible to actually compute a signature for the signer as well. So we need to first construct a special system of quadratic equations that can be solved easily, and then find a way to transform it into one that hopefully is indistinguishable from a randomly chosen one. We use the matrix notation discussed above for this. In particular, if the matrices have the form , with being a symmetric matrix, and being a matrix. Written in this block fashion, it makes sense to distinguish the first variables, called the vinegar variables from the last variables, called the oil variables. If we look at what this form of matrix does to the polynomial, we see that having that zero block in the lower right means that while vinegar variables are multiplied with all other variables, oil variables are only ever multiplied with vinegar variables, and never with each other. We also conveniently have exactly as many oil variables as we have equations to solve. And solving the equations is now very easy: First, randomly chose the value of the vinegar variables. Partially evaluating the polynomials, we will now have constant terms (where vinegar variable was multiplied with vinegar variable), and linear terms (where vinegar variable was multiplied with oil variable), but crucially, we do no longer have any quadratic terms, as we did not allow oil variables to be multiplied with other oil variables. In other words, we have linear equations with variables to solve. Which we can do by applying Gaussian elimination. This system will not always have a unique solution, but that is reasonably unlikely, and if it doesn’t, we can simply chose a different set of values for the vinegar variables.
This gives us a system of quadratic equations that is easy to solve, and this will be our private key, and what we actually solve when signing.
So how do we switch from this private system of quadratic equations to the public system? Well, with a base change, of course. This is a linear function on our variables, mixing them around, explaining the name of the scheme. We can write this using a matrix , which allows us to fully write down the private key and the signing algorithm:
A UOV private key is a matrix such that the public key can be expressed as . To sign, we first compute the hash of the salted message, chose random values for the vinegar variables, giving us as preliminary signature, leaving variables for the last m coefficients. We then compute , giving us linear equations, which we solve for , giving us a private signature . Since can be expressed as , and we just computed such that , we now know that , so is our signature.
To do this, we need to take the approach algebraists love to take, and get rid of the basis altogether, i.e. we now talk about some n dimensional vector space . So how can we describe the special property of our quadratic form, or its associated bilinear form, without explicitly referencing its matrix structure (and thus the specific basis)? Well, we made the matrix symmetric (since we ignore the whole “it’s actually characteristic 2, so it’s all weird” thing), and we know that symmetric matrices lead to symmetric bilinear forms, so we know that we are looking for m symmetric bilinear forms. The main property of the form in our special basis was that 0 in the lower right corner. The coefficients of a matrix of a bilinear form describe the result of the bilinear form applied to the corresponding basis vectors, i.e. , so having a 0 in this position means that there are m linear independent vectors which, when put into the bilinear form in both positions, will evaluate to 0. So to get rid of the basis, we need an m-dimensional subvectorspace of , with the property that for i from 1 to m. It is this subvectorspace which makes up the private key. Since it corresponds to the last m variables when choosing a basis, it makes sense to call this the oil space, containing vectors consisting of only nonzero oil variables above.
To continue our description of UOV without choosing a basis, we need to extend our oil space to the full vector space, by finding some space such that . Thankfully, there are tons of such vector spaces, and, as it will turn out later that the choice of vinegar space does not matter at all.
With the vinegar space chosen, we can now reformulate the full signing algorithm, without the use of base changes:
We know that all vectors have a unique representation as , with . So we know that , given the property of our bilinear forms. Choosing randomly, we again get a linear equation per bilinear form to compute , and in particular, if is not very unluckily chosen, there is now only one that will give the right value for all . Since the decomposition is unique, if we had chosen a different vinegar space, there would be a different vinegar vector that would have resulted in the same signature (assuming again that we do not get unlucky and end up with an underdefined system of equations and reroll). But we chose the vinegar vector at random anyways, so other than determining the lower dimensional space of unlucky vinegar vectors, the choice of the vinegar space has no consequence for our signing algorithm, as long as it intersects the oil space trivially to form the direct product, and even the basis we chose makes no difference, since we only use this vector space for choosing a random element from it, an operation that is independent from the choice of basis.
Let’s now look at the oil space, and what consequences different choices of basis have here. We assume that the vinegar space and oil space are fixed as above, and that we have chosen a random vinegar vector such that the system of equations has full rank. But then there is exactly one oil vector that solves for a particular right hand side, and that oil vector again does not depend on the basis we use for the oil space, just on the fact that it is in this oil space. So we can also chose the basis of the oil space basis as convenient. Note that, different from the vinegar space, this is not true for the oil space itself, which we had to secretly determine and now have no way of changing, just its basis.
Lastly, we can ask how likely it is for a given random dimensional sub space and dimensional sub space to intersect trivially. It turns out, this is again very likely (the chance of having a non trivial intersection is about one over the number of field elements). This means we don’t restrict our choice in oil space too much if we require it to intersect trivially with a specific vinegar space.
So, to put everything together: The choice of vinegar space and its basis has no real relevance to the signing algorithm, so we might as well chose the first unit vectors to span this space. This does not really restrict the choice of oil space, and within that space the choice of basis again does not matter. We obviously cannot chose this part of the basis as the unit basis, but we can chose the basis such that the last m coefficients agree with with the last m unit vectors, i.e. chose the basis of as , with being the m dimensional unit vectors. All in all, this means our base change matrix now looks like this: . Applying this base change to our public key as above, we get . So in order for the form to have the required shape, we need only that .
All of this taken together, this means that the only part of the public key that actually depends on the private key is the lower right block of the m quadratic forms. Which means that the rest of the public matrices can be chosen at random. The UOV competition entry cleverly uses this to make the public key much smaller, from bytes for the expanded public keys, to bytes for the compressed public key, using the 16 extra bytes as a seed to input into an XOF, to generate and . I, in turn, can use this property to keep the public key large, but hide amusing message in them, like the aforementioned python script.
While there are many schemes discussed in the currently ongoing second onramp for PQC signatures, Unbalanced Oil and Vinegar (UOV) is both one of the most serious contenders and also an extremely curious scheme. In this three part blog series, we will take a closer look.
In a previous blog post, I looked at how to recover an UOV public key from loads of valid signatures. That blog post very intentionally left out a lot of details about the actual scheme, like why it is believed to be secure, or how the private key actually works.
It belongs to a larger family of multivariate schemes, which is most famous for having most of their members broken, with paper titles ranging from the rather dry “Cryptanalysis of the oil and vinegar signature scheme” to the very memeable “Breaking Rainbow Takes a Weekend on a Laptop“. Interestingly enough, for a field with this many broken schemes, Unbalanced Oil and Vinegar has so far stood the test of time. In this first part, we will try to understand why the underlying hard problem, multivariate quadratic equations, is hard.
What solves polynomial equations
If you want to cut this blog post short, you can just read the last section, about why the problem is NP-complete. It is independent from the rest of the blog post, and I think slightly easier to understand. Doing so however, misses out on building some deeper understanding of what it means to solve systems of polynomial equations.
If you attended any form of primary eduction, you have probably learned the formula for “solving” quadratic equations, is . In fact, in German high school, we called this formula the “midnight formula” on account that you should be able to recite it without hesitation if your math teacher wakes you up at midnight and asks you how to solve quadratic equations. This approach is called “solving by radicals”. It solves a polynomial equation by expressing the roots of the polynomial with field operations and a special function , which returns the single positive real solution of .
If you take a step back, this is not super surprising. After all, the way I presented it above, all a radical means is assuming that you already have a way to solve an entirely different polynomial equation, and then making it weird by introducing such ill-defined concepts like the real numbers (yuck).
So what do we (as in algebraists) mean by solving a (univariate) polynomial equation? Well first we need to distinguish between reducible and irreducible polynomials. If the polynomial is reducible, than factoring it will give you new polynomials, and each solution of any factor is a solution of the original polynomial. If the polynomial is irreducible however, we just, sorta, do nothing, and just assume that is a solution, and try to express things with respect to that solution.
For UOV in particular, we are concerned with rational solutions, i.e. solutions that themselves are part of the base field. Thankfully, despite all of this rambling above, those are always well defined, even if you don’t have a formula for it: They are just the roots of the linear factors of our polynomial. When it comes to finding rational solutions, the good news do not stop here: Factoring polynomials (both over finite fields and over the rationals, and also over all sorts of other fields like ) is a problem of polynomial complexity, so there are efficient algorithms for computing the factorization, and by extend finding the rational solutions, of any univariate polynomial. And if you are a German high school student, after reading this section, you are officially allowed to answer with “it’s complicated”, roll over, and get a good night’s rest when your teacher wakes you in the middle of the night.
Gröbner bases
So far for solving univariate polynomial equations. But, as the name of the field “multivariate cryptography” suggests, what we really are interested in are multivariate polynomials, i.e. polynomials with multiple variables. We also need to solve systems of equations, i.e. multiple equations simultaneously. Here we first encounter something really weird about multivariate polynomials, by looking at multivariate monomials.
While univariate monomials, i.e. expressions of the form are a total well-order, i.e. all monomials compare with each other through divisibility, and there is a smallest monomial (1), the same is not true for multivariate monomials: We still get a natural partial order via divisibility (e.g. is divisible by and ergo bigger than ), not all monomials compare anymore, (e.g. is neither divisible by nor divides ). This quickly becomes a problem, for example division with remainder is no longer well-defined.
We can, however, fix this by extending our existing partial order (which, as an aside, is a lattice, which has nothing to do with lattices of lattice cryptography, which in turn for ML-KEM and friends are an order, which has nothing to do with the comparison thingy called order. Mathematicians are very bad at naming things.) to a total order. The easiest way to extend the order is by using the lexicographical order, where we first compare the degrees of the first variable, and if equal, compare the second variable, and so on, until we find differing degrees, which then decide which monomial is bigger (e.g. is bigger than , but smaller than ). This is not the only possible order, and the choice of order will become very important later.
With the order chosen, we can now go ahead and define division with remainder again, by taking the leading monomial of the divisor, checking whether it divides the leading monomial of the dividend, and if so, subtracting the appropriately multiple of the divisor from the dividend. We can do this repeatedly with a whole set of divisors, to end up with a remainder, but we will notice that the order of these divisors matters, and that in general our division with remainder algorithm lost a lot of the nice properties that it had in the univariate case.
Enter Gröbner bases. These are special sets of polynomials, for which division with remainder regains at least some of the useful properties they had in the univariate case. In particular, when using a Gröbner basis, the remainder is a canonical representative of the ring of all polynomials modulo the ideal generated by the set of polynomials. Why do we care about this? It turns out that there is a rather intimate relationship between the modulo operation, and the set where all polynomials simultaneously vanish, i.e. the solution of our system of multivariate polynomials, called the Nullstellensatz. You just know how important it is because we didn’t translate it from Hilbert’s original German. The details here go far beyond this blog post (as you might have noticed when I started talking about generating ideals etc, without warning the reader that they’ll need commutative algebra to proceed), and are thankfully not necessary to understand the basics.
For us, interested in particular rational solutions though, there is some value in looking more deeply into how a Gröbner basis for the lexicographical order looks like:
Given a system of polynomial equations (of dimension 0, don’t worry about that, though, it’s a technicality), the Gröbner basis with respect to the lexicographical order is an equivalent set of polynomial equations (i.e. each solution of one is a solution of the other), that specifically has the form , with being univariate in , being bivariate in , etc.
In particular, given such a Gröbner basis, we can find the rational solution by solving the last polynomial (which is univariate), taking each zero, partially evaluating the second to last polynomial obtaining another univariate polynomial, solving that, and so on. Note that this algorithm by itself might already be exponential: Nothing guarantees us that any given zero will end up with a valid solution after having factored tons of univariate polynomials, but in practice that is not usually the problem.
Finding Gröbner bases
What is the problem though, is finding the Gröbner basis to begin with. In fact, this problem is so complicated and interesting, that I decided to write an entire blog post about it, in case you haven’t noticed that I have not really talked about UOV so far, and won’t really mention the scheme other than as a motivating factor for all this until part 2.
So let’s finally look at the algorithm to find Gröbner bases, Buchbergers’s algorithm (there are slight improvements on this algorithm called F4 and F5, but they don’t drastically change things). The algorithm is simple enough to write it out in its entirety here:
buchberger(set of polynomials S) ->
list of polynomials S'
for every pair (p1, p2) in S:
let m1 be the leading monomial of p1
let m2 be the leading monomial of p2
let m be the lcm of m1 and m2
compute p = m/m1 p1 - m/m2 p2
reduce p by S with quotient and remainder
if p != 0, add p to S
reduce every element of S by S without it
return S if the loop adds no new polynomials
This algorithm is a beauty! Notice that, the way it is written, it is not even clear that it terminates, much less what complexity it has. The “simplest” argument I know as to why it terminates goes something like this: If we look at the ideal generated by the leading monomials of S, then the element p we add in each loop iteration, will either have a new leading monomial (otherwise it would have been reduced), not yet part of this ideal, or it will reduce to 0 and not be added. So for each loop iteration, this ideal of leading monomials strictly grows. But polynomials rings are Noetherian, and as such, every strictly ascending chain of ideals will eventually terminate. At that point, the algorithm returns. While this proves that Buchberger’s algorithm always terminates, it does so by invoking one of the strangest properties of commutative algebra, and it does so without giving a constructive proof which could be used to determine the runtime complexity. One can compute the runtime complexity, by doing things more carefully, and arrives at the wonderful terms like for the degree of the polynomials in the eventual basis, so yeah, it might be a while, and even just writing down the basis is not trivially possible. In fact, in practice it is the space complexity of Buchberger’s algorithm which destroys all hope of ever getting a solution far before the time complexity becomes relevant.
And yet, algebraic geometers are so desperate for Gröbner bases, that they will continue running this algorithm for their current pet problem, based on nothing more than just hope. And it turns out, that hope is not always misplaced. I mentioned monomial orders before, and it turns out that Gröbner basis computation very sensitively depends on which monomial order one choses. A problem which will just run out of memory in one order might finish in seconds in another. You can also vary when you reduce which polynomial by which set, and come up with all sorts of fun distributed computation problems that will greatly influence the runtime of this algorithm. And what is nice is that once you have one Gröbner basis, you can quite efficiently compute other Gröbner bases as well, so nothing stops us from first computing the Gröbner basis in the more efficient graded lexicographical order, and then switching to the desired lexicographical order for cheap.
And this is the biggest weakness of multivariate cryptography. Where lattice cryptography has its nice worst case to average case reduction, multivariate cryptography has a very hard worst case problem, but a very finicky to control average case. So finicky in fact that often authors will just state how much RAM they spend on trying to find a Gröbner basis, since there is no better way of estimating runtime.
Multi-variate quadratic equations solving is NP-complete
Now to the last, and as promised independent section of this blog post, showing that solving multivariate quadratic equations is NP complete. We do this by reducing the problem to SAT, boolean satisfiability. For conciseness, we only do this for multivariate polynomials over , the field with 2 elements, but showing it for every other field is not substantially different.
We do this, by looking at one multivariate polynomial in particular: .
Since our field has only two elements, we can quickly check what evaluates to: . In other words, if we associate 0 with false and 1 with true, f is equal to NAND. Famously every boolean circuit can be expressed just by using NAND gates, and wiring up gates is the same as chaining function calls, which in turn is the same as substituting polynomials. This means every boolean expression equals one multivariate polynomial, with the degree being exponentially bounded by the circuit depth. In order to get back to a quadratic system of polynomials, we now introduce a new helper variable Y for each variable X that has a degree higher than a square, by adding the polynomial to our system of polynomials. This allows us to halve the degree of the polynomial again, and taken together, we get a polynomial bounded system of quadratic equations (and if we do both steps together, we never explode the degree of the polynomials in illegitimate ways). This reduces SAT to MVQ. On the other hand, given a possible solution, verifying it can be done simply by evaluating quadratic polynomials, an operation that itself is polynomial in time, so MVQ is in NP, making it NP-complete.
But remember, this only goes for generic systems of multivariate quadratic equations, and is no proof that UOV, which we will discuss in the next part, is even worst case hard, much less does it make statements about the average case complexity.
Yesterday, Chandler asked about an overview of the new PQC algorithms, including hybrids, for non-cryptographers. And since I’m currently procrastinating writing something about TLS, I might as well write that overview first.
Unfortunately, I am a cryptographer, which means I easily forget that the average person probably only knows what AEADs, Key Agreements, and of course Digital Signatures do.
XKCD no. 2501 “Average Familiarity”
So, I will do my best, but please tell me where a bit more detail is needed.
Overview
NIST has standardized three new algorithms, going by the names ML-KEM (aka FIPS 203 aka Kyber), ML-DSA (aka FIPS 204 aka Dilithium) and SLH-DSA (aka FIPS 205 aka SPHINCS+). The first is a Key Encapsulation Method, the other two are digital signature schemes. One thing they all have in common is their comparatively much larger sizes for public keys, ciphertexts, and signatures.
Additionally, I will also discuss X-Wing, a hybrid Key Encapsulation Method combining both classical and PQ algorithms, which is currently making its way through IETF.
Key Encapsulation
What is a KEM
We start of this overview of PQC algorithms with a new primitive, key encapsulation methods (KEMs). Technically, KEMs aren’t new, it just turns out that, while they are arguably the superior way of dealing with asymmetric encryption, they haven’t been used in very explicit ways.
So what is a key encapsulation method? Basically it is a primitive with the following interface, in some fake programming language vaguely resembling C++:
Here, you can see the close relation to asymmetric encryption, essentially a KEM is cryptographers saying that you shouldn’t actually decide what you want to encrypt, and instead that choice should be made for you. There is a good reasons for that: Asymmetric cryptography is far slower than symmetric cryptography, so really you should only ever encrypt a symmetric encryption key anyways, and a KEM just always does this for you. There is another advantage to always encrypting random numbers: It makes designing a cryptographic primitive far easier, because now the cryptographer doesn’t have to account for people encrypting “The eagle has landed” over and over again, and expecting that to be secure.
As an example, let’s look at RSA-KEM, a classical KEM that unfortunately never got the popularity it deserved:
pair<ByteString, Ciphertext> Encapsulate(PublicKey pk) {
// Select a random number between zero and the modulus.
BigInt msg = Random(0, pk.n);
// Hash the random number to obtain the shared secret.
ByteString shared_secret = Hash(msg);
// Compute msg^e mod n.
Ciphertext ct = ModPow(msg, pk.e, pk.n);
return make_pair(shared_secret, ct);
}
Pseudocode for RSA-KEM. This is an actually secure and standardized way of using RSA.
Basically, this is RSA as you learned it in high school/college, without all that weird optimal padding stuff that OAEP has to add just to allow you to encrypt your “arbitrary message” which usually is just random numbers anyhow.
So now that we know how to build a KEM out of RSA, let’s quickly also do so with elliptic curve, so we can accurately compare to PQC algorithms. Actually, it’s not even so much elliptic curves, but any Diffie-Hellman like key agreement scheme. So again, with fake C++ inspired pseudo code:
Pseudocode for ECIES-KEM. This is not a secure KEM as is, but the details to make it secure are not interesting here.
Basically, to use ECDH as a KEM we create an ephemeral key pair, use the ephemeral public key as ciphertext and use the key agreement to create a shared secret. Again we can see how it simplifies the algorithm to not let the caller chose what is encrypted, here by using that we cannot actually control which secret is agreed upon, just that it is random.
KEMs do have one disadvantage over asymmetric encryption schemes: You can no longer encrypt the same message to multiple recipients, since each encapsulate call will create a new, random shared secret. There is a way to recover this ability, through using something called an mKEM, but that would go beyond the scope of this blog post and is not directly feasible with what NIST has standardized.
This section has gone on long enough without mentioning anything actually post-quantum, so it is high time that we change that, with the introduction of ML-KEM, née Kyber, into the mix. ML-KEM is, as the name implies, a KEM, and comes in three different sizes, called 512, 768, and 1024. Funnily enough, those numbers refer to some abstract mathematical thing (the lattice rank), and never show up in the code itself, so calling them 2, 3, and 4 (the module rank) would probably have been the better choice.
Algorithm
Public Key Size
Ciphertext Size
Speed
Security Scaling
RSA-2048-KEM
~256 bytes
256 bytes
Very fast encaps, slow decaps
subexponential*
ECIES-KEM (X25519)
32 bytes
32 bytes
fast encaps and decaps
exponential*
ML-KEM-768
1184 bytes
1088 bytes
fast encaps and decaps
exponential
X-Wing
1216 bytes
1120 bytes
fast encaps and decaps
exponential
Overview of different KEMs at the recommended (by me) parameter sets. *: Unless a quantum computer is build, when it becomes polynomial
In this table, you can see an entry I haven’t mentioned so far, X-Wing. X-Wing is what is called a hybrid KEM, combining both X25519 and ML-KEM-768 into a single primitive. You can tell that by noticing that the public key and the ciphertext are just concatenated versions of the two schemes. The real magic of X-Wing happens in its key derivation function, where it combines the two shared secrets in such a way that the resulting primitive is a secure KEM as long as either X25519 or ML-KEM-768 are a secure KEM.
All in all, the extra cost of the X25519 key agreement is likely so small that you will want to go with X-Wing for most practical applications.
Security Levels
You might have noticed that I only put ML-KEM-768 in the table above, and that X-Wing does not have any parameter choice at all, only being defined for X25519 and ML-KEM-768 as constituent parts. The reason for that is a bit longer rant on how security levels are not the most useful tool to describe the security of cryptographic schemes. There are two main arguments for this: First, looking at RSA-2048, we get a security level of around 112 bits, and subexponential scaling means that we have to more than double the key size in order to double the security level. 112 bit is somewhat low, but for all we can currently predict, RSA-2048 will be broken at right around the same time as RSA-4096 will be, by a cryptographically relevant quantum computer. In other words, there isn’t really a good reason to use a larger RSA modulus, in terms of security strength.
On the other side, ML-KEM-512 is believed to have 128 bits of security, but the bounds there are quite tight and it is very possible that future improvements drop the security further. That has led to a sort of consensus among many cryptographers that it is best to use ML-KEM768 by default, with this consensus being reflected in the choices X-Wing made as well (full disclosure: I am not a X-Wing coauthor, but have been asked about my opinion on parameter choices by them).
Security and public key/ciphertext size scales mostly linear in ML-KEM’s security parameter, so ML-KEM-512 has a 800 byte/768 byte public key/ciphertext and ML-KEM-1024 has a 1568 byte public key and ciphertext. Performance scales quadratically in the security parameter, which makes using larger security levels a lot less painful than with RSA and elliptic curves, which scale worse than cubical. To finish this section on security levels, while there is mostly a consensus around ML-KEM-768 being the recommended choice, there is one important outlier here, with the NSA recommending ML-KEM-1024 for all clearance levels.
Implicit Rejection and Misbinding
There is a weird property that ML-KEM has, that warrants its own subsection, implicit rejection. This deals with the question of what happens when an adversary manipulates a ciphertext instead of creating a fresh one, or constructs an invalid ciphertext. What is weird here is that ML-KEM’s decapsulation method will detect such a manipulation, but instead of failing, it will return a “shared” secret that is only known to a party with access to the private key. While this behavior seems weird at first, it mimics what RSA-KEM and ECIES-KEM do involuntarily in this case as well, but it is a strange behavior that has some even stranger side effects, and really only exists because of the specific metrics that the NIST competition incentivized, and not because it is necessarily the best choice in practice. One of the even stranger side effects is on ML-KEM’s binding properties, a property related to the invisible salamander properties some AEADs exhibit. Those were first discussed in a paper with the excellent title “Keeping up with the KEMs”, and I also had to chime in on the topic, and, trying to keep with the pun, wrote “Unbindable Kemmy Schmidt”. Compared to invisible salamanders, these attacks are far harder to imagine being exploitable in a real world setting, but there is an easy and FIPS compliant way to deal with the more powerful attack, by using the 64 byte seed as the private key instead of the expanded version that ML-KEM also defines. This has led to libraries like BoringSSL making the seed the standard representation of the private key on the wire, which has the side benefit of being very small.
More on Performance
To conclude this section on KEMs, a few more words on performance. I already mentioned that performance scales quadratically in the security parameter, but, another thing worth noting is what is needed to make ML-KEM fast in practice. There are two main parts to ML-KEM that influence its performance: Decompressing a matrix using SHAKE (a SHA3 variant) and performing matrix-vector multiplication on this matrix. Different from both RSA and ECC, this is not done modulo a particularly large prime, with the prime used, 3329, comfortably fitting into a 16 bit integer, with 4 bits left to spare. Together, this means that to accelerate performance, you need to accelerate SHA3 and/or use vector instruction sets. If you want to get even more performance, the remaining somewhat costly part of ML-KEM is a NTT, i.e. a Fast Fourier Transform, so a vector unit that can speed those up will likely also help ML-KEM.
Another important note on performance is the caching behavior of ML-KEM. As mentioned, one of the most expensive steps in ML-KEM is the expansion of a seed into a matrix. This matrix is part of the public key, and does not change between encapsulate or decapsulate calls as long as the same public key is used, so it can be cached if memory is plentiful. On the wire, the matrix here is only 32 bytes in size (and the reason why the public key does not scale perfectly linearly), expanded it becomes byte in size, with k = 2, 3, 4 being the security parameter. So if you have 4.6 KB to spare, and you want to do multiple encapsulation or decapsulation operations with the same key, or created an ephemeral key that you will immediately use to decapsulate with a roundtrip later, keep the fully expanded key in memory between operations and don’t unmarshal from the wire format every time.
The performance of X-Wing is pretty much what you get when you have to run both X25519 and ML-KEM together. You can technically parallelize these calls right up to the key derivation step, but that will likely just result in race conditions and not have a major impact on performance, since both are decently fast, as far as asymmetric cryptography is concerned.
Digital Signature Schemes
With the detailed discussion of KEMs out of the way, we can get to digital signatures. On the primitive side, those are the same digital signatures you are probably familiar with, using the same interface as ECDSA or RSA signatures. For completeness sake, here is the interface:
API for Digital Signatures, in some weird pseudo C++
This makes the signature schemes NIST standardized far more of a drop-in replacement for classical schemes. Here they are in a comparison table:
Algorithm
Public Key Size
Signature Size
Speed
Security Scaling
RSA-2048-PKCS1
~256 bytes
256 bytes
Slow signing Very fast verifying
subexponential*
ECDSA
32 bytes
64 bytes
Fast signing and verifying
exponential*
ML-DSA-65
1952 bytes
3309 bytes
Fast signing and verifying
exponential
SLH-DSA-SHA2-128s
32 bytes
7856 bytes
Slow signing, decent verifying
exponential
Overview of different Digital Signature Schemes at the recommended (by me) parameter sets. *: Unless a quantum computer is build, when it becomes polynomial
Again, we can see that the PQC algorithms, in particularly ML-DSA are comparable in speed, but have far larger overhead. At first, SLH-DSA’s public key size seems like an exception, but if you want a small signature public key, you can always just hash the public key and attach the unhashed public key to the signature, in which case ML-DSA would take the lead again. The signature size problem is in fact so large that it poses a significant problem for TLS, necessitating the blog post I’m procrastinating on.
ML-DSA again comes in three different flavors, ML-DSA-44, ML-DSA-65, and ML-DSA-87. The security parameter here is not a two digit number, but two single digit integers written without a space in between them. Since confusing lay people seems to have been an explicit security goal here, the authors went with the parameter that actually shows up in the code (aka the module ranks), instead of ML-KEM’s theoretical only lattice rank, so (4, 4), (6, 5), and (8, 7) correspond to ML-KEM’s 2, 3, and 4.
In order to compete on the confusion metric, SLH-DSA comes in way too many flavors. It mainly requires a hash function, with NIST allowing both SHA2 and SHA3/SHAKE as possible choices, in three different sizes each. There are also variants for faster signing at the cost of even larger signatures, and the prehashing thing they added for some reason which I’ll rant about below, totaling 24 different versions of SLH-DSA, of which maybe 2 are useful in practice as far as I can see.
Security Discussion
I again made the choice of parameters in the table for you, but in this case ML-DSA-44 is not quite as tightly scraping by the security level, making it somewhat more acceptable. The overhead again scales linearly in the security parameter, with ML-DSA-44 having 1312 byte public keys and 2420 byte signatures, and ML-DSA-87 having 2592 byte public keys and 4627 byte signatures. The NSA again requires ML-DSA-87 for all applications (and sadly dislikes SLH-DSA).
SLH-DSA’s security deserves some special discussion. You might have noticed that I recommended the smallest parameter choice here, and that is not just due to it otherwise being pretty much intolerable, with 16 KB to 50 KB signatures at the higher/faster settings. SLH-DSA has a proof that reduces its security to that of the underlying hash function, that is as long as the hash function is secure, SLH-DSA based on the hash function is secure. Since hash functions by now have been very well understood, we can be more aggressive with the parameter choice and use the same 128 bit security level we also use for our current elliptic curve based cryptography.
This fact also makes SLH-DSA uniquely suited as a replacement for use cases where the public key cannot be rotated easily, in particular signatures used to verify the integrity of firmware updates for secure boot. It also helps that all you need to implement SLH-DSA is an implementation of the hash function (which you then proceed to call an ungodly amount of times), which makes SLH-DSA uniquely well suited for hardware applications.
For all other use cases, ML-DSA wins on both overhead and performance, so anything that can be updated to account for the unlikely event of potential mathematical breakthroughs is probably better served using ML-DSA.
Performance Discussion
As mentioned, SLH-DSA uses hash function calls. A lot of hash function calls. Accelerating those is probably a good idea if you want to use SLH-DSA.
SLH-DSA has another curious security property: Its security depends on how many signatures have been created with the scheme. The NIST parameter sets are secure as long as “only” signatures are created. This restriction does not apply to ML-DSA, which provably does not degrade in security as more signatures are produced. This property allows for another potential trade-off, when it is known that less signatures are actually produced over the lifetime of a key, again something that makes it better suited for firmware signatures. In a way, this can be seen as a sliding scale of statefulness of the signature scheme, with stateful hash-based signatures on one end, requiring keeping exact state of the signatures that have been produced, to keeping a rough count of signatures that have been produced in the modified parameter sets, to SLH-DSA not requiring any such count, unless you can reach signatures per public key in your application (Not strictly speaking impossible, but even at Google’s scale very, very unlikely to happen in a practical design). NIST has promised to write a SP about the modified parameter sets, which will help with the security – performance tradeoff even further.
With this, we can move on to discuss ML-DSA. The algorithm used there is closely related to the one used in ML-KEM, so the discussion there applies here as well, SHA3, vector instruction sets, and NTT being the biggest things to accelerate. The prime used here, 8,380,417, is slightly larger, but still comfortably fits in a 32 bit integer. This larger prime also makes the cached matrix a lot larger, (notice the 4 instead of 2, to account for 32 bit integers instead of 16 bit integers), which means that ML-KEM-65 will need 30 KB of memory to cache its matrix when signing/verifying with the same key multiple times (16 KB for ML-DSA-44, 57 KB for ML-DSA-87).
Another quirk of ML-DSA, important for hardware implementations in particular, is that the raw signing procedure is not always successful, and has to be repeated until a signature can be obtained. This means the implementation technically requires a while loop, although one can alternatively also just calculate an upper bound at which the probability of not being able to find a signature becomes vanishingly small, which NIST has done and added as an allowed alternative to the standard.
Randomized Signing
Both ML-DSA and SLH-DSA can create signatures in a randomized or a deterministic fashion. Classically, this has been a discussion in the case of ECDSA, with the argument in favor of deterministic signatures being that a signer with insufficient entropy can still produce secure signatures. The argument in favor of randomized signatures is that they are more robust against certain type of fault injection attacks, but all in all, neither argument has been particularly convincing to me. Not having entropy available basically destroys all ability to do secure cryptography, so salvaging one part of one primitive is rarely going to make a difference. On the other hand, fault attacks are essentially asking whether an entirely different algorithm that just happens to share some instructions with the original is secure, which usually isn’t the case.
Thankfully, in the case of PQ signatures, we do not have to choose. The randomized variant in both cases devolves seamlessly into the deterministic variant if no entropy is available, so always using the randomized option is the more secure choice, and has no performance implications. If one knows that no entropy is available, the deterministic algorithm can be used to be more honest about the situation, but really randomized should be the default choice.
There are some exotic protocols that require signatures to be deterministic, so use the deterministic version in those cases as well, but you are unlikely to run into those by accident.
Hybrid Signatures
Similar to KEMs, signatures can also be hybridized. Where KEMs needed some borderline magical key derivation functions to achieve the “secure if either is secure” property, for signatures that can be done with the somewhat simpler “logical and” between the two verification calls. There are some pending RFC drafts for this as well, but the necessity here is not as pressing. On the ML-DSA side, if you are able to change your public key and given that there is no secrets to leak, just forgeries to avoid, we can switch the PQ scheme if we are aware of any weaknesses. For SLH-DSA, this gets even stronger, since all signature algorithms, including all classical signature algorithms, are only secure if the hash function used in the scheme is secure, so combining SLH-DSA with another scheme is not really useful.
That being said, a classical ECDSA/EdDSA or even RSA signature is so tiny in comparison that adding it to the ML-DSA signature is not going to change things much, so you might as well, it does protect you against mathematical advances that happen outside of the public view.
Prehashing, a Rant
I very briefly mentioned prehashing above, as a reason why SLH-DSA has another factor of 2 more variants. Prehashing technically also exists for ML-DSA, where it makes even less sense, but I’m getting ahead of myself.
As you might be able to tell, I don’t have the highest opinion of prehashing, but let’s start at the beginning:
In the case of RSA-PKCS1, RSA-PSS, and ECDSA, the very first operation the algorithm does is to hash the message down to a more manageable size. This can be used by HSMs and remote signing oracle by computing the hash outside of the HSM/locally and only transmitting the hash of the message to be signed. However, doing this has some implications for some properties beyond forgability resistance, such as the public key recovery I discussed in the previous blog post, and more importantly something called non-resignability, which NIST encouraged schemes to achieve. This led to both ML-DSA and SLH-DSA departing from the simple hash as a first step paradigm, and instead mixing the message into the scheme in a more complicated fashion. In the case of ML-DSA, this “more complicated” fashion is just a hash of the public key together with the message, which still can be computed outside of the HSM/remote signing oracle, but in the case of SLH-DSA even that is not possible.
FIPS 204 explicitly allows for ML-DSA prehashing the message by computing this first hash in a different place, and in my opinion that is the way prehashing should be accomplished there.
For SLH-DSA, this isn’t possible. In my opinion, that simply means that it should not be done, and that instead any protocol (where a protocol is not necessarily interactive) that requires the message size to be small should specify the hashing of the message on the protocol level, instead of trying to make a primitive, which does intentionally not support such an operation, to support it anyways. Unfortunately, this is exactly what NIST has done, technically for both SLH-DSA and ML-DSA, with ML-DSA also allowing for the actual prehashing as described above. What this means is that there are two versions for each signature scheme and parameter set, obtained by either prefixing 0x00 to the message or prefixing 0x01, a hash OID, and the hash of the message before feeding the so manipulated input into the underlying signature scheme, thus essentially defining a protocol on the primitive level. You should not use the same key for both prehashed and not-prehashed messages, mostly due to the primitive otherwise not being a well-defined signature scheme anymore (i.e. the API defined above would have to change to allow another input when signing/verifying), and if you fix whether a key is always used prehashed or always used non-prehashed, you just defined a protocol, and adding this step to the primitive was unnecessary.
Anyways, it’s a thing the standard allows for, but ideally we should all just collectively ignore that this option exists and always use the non-prehashed variants (with exception of the true prehashing of ML-DSA), and just define our protocols to correctly work with our use cases.
A while ago, I was bored and wrote a Twitter post on how to find an integer if you only know the fractional part of its square root. My Twitter is private these days, and lies unused, but I still get questions about this topic from time to time, so I decided to put it into a blog post on here.
Why would one care about reconstructing an integer from the fractional part of its square root you might ask? It turns out there is some crank out there who claims that this can serve as the basis for his brilliant crypto system, so showing that this reconstruction is possible is the same as a key recovery attack.
Computing Square Roots
As usual with crank cryptography, the official documents are very light on actual description of the algorithm, so we will have to nail down the definitions first before we can actually attack the cryptosystem.
From what can be inferred from the documents, we first select a secret -bit integer that is not a perfect square (if is a perfect square the attack won’t work, but the algorithm will only produce zeroes, so it is trivially distinguishable). We then produce a “random” bitstream by looking at the digits of , i.e. the primitive we are studying is a DRBG.
Before we look at the security of this algorithm, lets first take a quick glance at how it otherwise works for a DRBG. The best algorithm to compute a square root is using Newton’s method to first compute the inverse square root, and then recover the square root via multiplication with the number itself. In other words, apply Newton’s method to the function . This function clearly has a zero at , which Newton’s method should find with quadratic convergence, assuming we started somewhere halfway decent.
For Newton’s method we need to first compute the derivative of our function, which is just .
Newton’s iteration then gives us:
Now we can see why we prefer to compute the inverse square root with the iteration: The formula happens to only ever divide by 2, so it is far cheaper then having to divide by , which we would otherwise have to do if things didn’t cancel out this neatly.
Quadratic convergence means we roughly double the number of correct digits each iteration step, but looking at our iteration step, we need to multiply several -bit precision numbers, so the total time complexity of this algorithm should be with bits of space complexity.
This is abysmal. A DRBG should have linear time complexity and constant space complexity, i.e. the cost of producing an extra bit of randomness should not depend on how much randomness was previously created. It seems like even our crank caught wind of that, because he used this generator just to seed a Blum-Blum-Shub generator, which, while one of the slowest DRBGs we have, has linear time complexity and constant space complexity. You can also add a backdoor to it, which I guess is a property you can have in a DRBG, if you like it.
Lattices enter Stage left
With the ranting about how badly this DRBG performs aside, to the main piece of this article, how to break it. We will use a well-known technique to tackle Diophantine equations with some lattice math for this.
For this, let’s get some -bit stream of of our -bit integer . In other words , for some unknown integer . Let’s set . With that we have , with both and being unknown integers. This isn’t looking very promising, one equation with two unknown variables, but then you realize that is known to a precision high enough to contain more than enough information about both of these integers, if we can just tickle it out of it. It’s a linear equation (and in fact one of the goals of the substitution was to make it linear), and if you paid attention in one of my previous posts, a linear equation when the coefficients are integers is what lattices live for. We still need to manipulate it a bit further before we get to the actual lattice, though. First, we need a large number, let’s take something like . The main thing that matters here is not so much the value of itself, just that it is large enough for what comes next. And what comes next is a lattice, generated by the vectors
In other words, the elements of our lattice are the vectors of of the form , with integers. In particular, the vector is a vector in our lattice, according to our previous calculations. Since is so large, this vector is fairly close to , given that both and are roughly , i.e. only bit integers. If we vary or though, we either have to make them very large, or we will never get as close in the first coordinate, as we carefully balanced things so that our linear equation works out.
In other words, if we find the lattice vector closest to , we have found our integers and with them .
But wait, I hear you say, isn’t that the Closest Vector Problem (CVP), known for being hard to compute. Well indeed it is. And it is hard to compute. For higher dimensional lattices. For a rank 2 lattice embedded in three dimensions, it’s not. You simply reduce the lattice basis above, express in this basis, round the coefficients to integers, and, as by magic, the coefficients will be the unknown integers. I’ve implemented this algorithm here, and here is a sample output:
Lattice reduction for two dimensional lattices is incredibly fast, resulting in an algorithm that is nearly as fast to break as it is to compute in the first place. The author of the algorithm suggested a hardening technique of varying the offset used, i.e. discarding some of the keystream. This of course doesn’t do anything, as the attack is fast enough, and the computation of the keystream is slow enough, that you can simply bruteforce all possible starting points, changing by a power of 2 as necessary to account for the discarded bits.
While this algorithm is obviously bogus for cryptographic purposes, the general technique for solving Diophantine equations with lattices is a useful tool to understand and study, similar techniques are for example used in Coppersmith’s attack on RSA with small exponents and are valuable to understand for anyone with an interest in discrete mathematics.
It’s now been several times that I had a conversation with some security folks that went something like this:
Them: “I wished this lattice stuff was easier, like RSA, I tried to read up on it but it was just so complex” Me: “I think RSA is actually a bit more complicated than Learning With Errors, the didatics on it are just not as far along” Them: *Pressing X to doubt* Me: “Fine, I’ll explain it, against my will. I am just going to note here that I am basically forced into this and derive no joy whatsoever from explaining lattice cryptography.”
So after having done that a few times, I figured I should put some of it into a more scalable, written form.
Prerequisites: A bit of Modular Arithmetic and a bit of Linear Algebra.
So what on Earth is a lattice?
A lattice is a free, finitely generated \mathbb{Z}-module usually embedded into a finite dimensional real vector space.
That’s a bit of a mouthful, so let’s break that down a bit.
The term module is just mathematicians being fancy and using a different word for “vector space, but over a ring” (In case you don’t know what a ring is, for this blog post, just replace that term with \mathbb{Z}, the integers. It’s a numbery thing where you can add, subtract, and multiply, but not necessarily divide. In case you don’t remember vector spaces, it’s where vectors live. You can add vectors, there is a zero vector, and you can multiply vectors with elements of the base ring/field to scale them).
Finitely generated means that there is a finite number of elements that generates it, in other words every element x in our module can be written as x = \sum_{i=1}^n a_i g_i, with a_i \in \mathbb{Z} and g_i being our finite set of generators.
This leaves us with free. A module is free, when it actually behaves like a vector space and doesn’t do any weird ring shit. Modules love doing weird ring shit, so this qualifier is unfortunately very necessary. More formally, it means that our module has a basis, i.e. that we can choose the g_i so that the sum above is unique. In that case, any such set will have the same length, which we call the rank of the module, because calling it the dimension would make too much sense and we can rewrite the module to be \mathbb{Z}^n. In other words, for any ring R all free, finitely generated R-modules are isomorphic to R^n.
So we have some integer vectors, and we want to embed them into a real vector space. To avoid some technicalities, I will only talk about so called full rank lattices, where the lattice rank is the same as the dimension of the vector space. I will also not go into the technical definition of embedding, it’s a fairly decent word as math words go and means pretty much that, the lattice is placed inside the vector space.
One thing to note is that there is more than one way to embed \mathbb{Z}^n into \mathbb{R}^n. Let’s take n=2 as example, so we can draw some pictures.
The lattice \left\langle\left(1, 0\right),\left(0, 1\right)\right\rangle
The simplest way we can embed \mathbb{Z}^2 into \mathbb{R}^2 is by just mapping things trivially and looking at all points with integer coordinates. Unsurprisingly, we get a grid.
The lattice \left\langle\left(1, 0\right),\left(\frac12,\frac{\sqrt{3}}{2} \right)\right\rangle
If we want to be a tad bit more creative, we could try this hexagonal pattern. We can immediately tell that these two lattices are materially different. For example, in the first lattice, every lattice point has four closest neighbors, while in the second lattice we have six closest neighbors. As every board game nerd will tell you, the difference matters. A lot.
There are far more ways to create 2-dimensional lattices. So many in fact that you can prove all sorts of things about elliptic curves just by looking at 2d lattices, but that is a different blog post.
So to recap:
A lattice is a copy of the \mathbb{Z}^n, embedded into the \mathbb{R}^n.
Lattices have bases. They behave nicely, and don’t do weird ring shit.
The way the lattice is embedded matters.
Hard problems in lattices
While lattices are fascinating by themselves, we want to do cryptography, so we need to have hard problems. The two hard problems we will look at are called the Shortest Vector Problem (SVP) and the Closest Vector Problem (CVP).
The Shortest Vector Problem is the question “What vector other than 0 is the shortest vector in this lattice”. The zero vector is in all lattices and has length 0, so if we didn’t exclude it it would not be a very interesting problem.
The Closest Vector Problem on the other hand answers the question “Given a vector x, not necessarily in the lattice, which point in the lattice is the closest point to this vector?”
Answering (pink) the CVP for the vector \left(\frac53, \frac34\right)(red)
Good Basis, Bad Basis
At first, it might seem strange that the CVP and the SVP are considered hard problems. After all, you probably didn’t need to even get out a calculator or measuring tape to solve that example CVP, and I didn’t even bother to prove that 4 neighbors, 6 neighbors stuff which is basically the SVP, so what is supposed to be so hard about this?
The problem is, we only looked at this problem in 2 dimensions. But for lattice cryptography, we use something more like 768 dimensions. Unfortunately, graphics cards have trouble rendering those, so we will have to build some intuitions with numbers.
In the example we found that the closest vector to \left(\frac53, \frac34\right) is the lattice point (2, 1). How did my computer calculate this closest vector? Well I told it to round \frac53 to 2 and \frac34 to 1. Exciting stuff.
Let’s look at a completely, totally different lattice, the one generated by \{(2, 3), (5, 7)\}. If we now want to know what is the closest lattice point to (\frac53, \frac34), we first need to change basis to our lattice basis, round, and change back to the standard basis. We see that (\frac53, \frac34) = -\frac{95}{12}\cdot(2, 3) + \frac72\cdot(5, 7), rounding gives us -8\cdot(2,3)+4\cdot(5,7) = (4, 4). Let’s plot this:
The starting point (red) and the “closest” point (pink)
Wait, what? First of all, it turns out, this completely, totally different lattice is the same lattice as before, because (1,0)=-7\cdot(2,3) + 3\cdot(5,7) and (0, 1) = 5\cdot(2,3) -2\cdot(5,7). Turns out, I “accidentally” just used a different basis of the very same lattice. But why did our rounding trick not work? Let’s work backwards: Our solution should be (2,1) = -9\cdot(2,3)+4\cdot(5,7). So we almost got there, but rounding was still off by one in the first coordinate. In 2 dimensions, that’s not a big deal, just brute force by adding or subtracting 1 from each coordinate and see if you find a closer point. Of course, if the dimension is something like 768, brute forcing isn’t going to help.
This means that there are good bases and bad bases. In a good basis, we can just round the coefficients to solve the closest vector problem. In a bad basis however, if the dimension is high enough, you are hopelessly lost. And it turns out the bad bases outnumber the good ones, and if you have a good basis and want a bad one you just randomly base change a bit. (The example basis was literally my first try).
Now there is a way to go from a bad basis to a good basis, with a method called lattice reduction. But this blog post is already too long, so I won’t go into that. Suffice to say it’s hard to get a good enough basis in high dimensions.
A problem that is hard, but only if you don’t know some secret? This is very promising, let’s do some cryptography!
And how do I encrypt with this?
With all that lattice knowledge, we can dive right into learning with errors.
As parameters, we need a prime q, and lattice rank n. Popular choices are primes like 3329 and ranks like 768. One somewhat sour note is that we will unfortunately only encrypt a single bit.
To generate a key, we need a matrix A, where we take the coefficients uniformly at random between 0 and q. This matrix could theoretically be a public parameter, but choosing it per key makes it impossible to attack all keys at once.
The next thing we need are two vectors, s and e, with small coefficients. And by small we usually mean something like -1, 0, or 1. Maybe the occasional 2, but not larger. We then compute t = A^Ts + e \mod q and make (A, t) the public key, keeping s for the secret key.
To encrypt, we will need two more vectors r and f, also with small coefficients and a small integer g. We kind of do the same thing as with key generation and compute u = Ar + f \mod q as well as v = t^Tr + m\cdot\frac{q-1}{2}+g \mod q. To build some intuition let’s look at what size those terms have. Since we multiplied with a bunch of uniformly distributed stuff, t and u are also uniformly distributed. g as discussed is small. m\cdot\frac{q-1}{2} is either 0, a number generally considered fairly small, or \frac{q-1}{2}, a number which, modulo q is the largest possible (we allow negative numbers, so if we make it any bigger it just wraps around). Since t was uniformly distributed, t^Tr is as well. Which is good, since that means it masks whether our message term is big or small, and with only a single message bit, we should better try protecting it.
So how do we decrypt? Easy, just compute m' = v - s^Tu \mod q and output 0 if it’s small and 1 if it’s large. Since
The first two terms cancel. The last three terms are small, more precisely not larger than 2n. So m' is large if and only if m was 1, at least as long as we choose our parameters so that the rank is not too large compared to the prime.
Cherchez la lattice
So you might say, that’s nice and all, but where is the freaking lattice? All that stuff about closest vectors and bad bases and so on, it doesn’t look like we actually used any of it. And you’d be right. Lattices are kind of weird in that they are everywhere in arithmetic number theory, but they like to hide a bit sometimes. So let’s find this lattice, by attempting to break this scheme.
We want to recover the secret key s from the public key A, t = A^Ts+e \mod q. Let’s do this in two steps. First, we try to find any vectors s' and e' that solve t=A^Ts'+e'\mod q, without caring whether or not they are short, and then we can try to modify them to be short.
We can rewrite our equation as (A^T, \operatorname{Id}, q\operatorname{Id})(s', e', k) = t with k being some integer vector that we just use so we don’t have to worry about the \mod q part. This is solving a linear equation over the integers. It’s not quite as straightforward as the standard Gaussian algorithm, but a small modification by Smith will solve it and give us both a special solution (s', e', k) and a basis of the kernel of (A^T, \operatorname{Id}, q\operatorname{Id}). Recall that any solution, including the short s and e we are looking for differ from s' and e' by an element of the kernel.
Hmm, looking more closely at that kernel, it is a \mathbb{Z}-module by virtue of being a kernel, it has a basis, so it is free, and the basis is finite, so it is finitely generated. We don’t really care about the last n coefficients though which we only needed for the modulo, but we can just drop them, and the result remains a free, finitely generated \mathbb{Z}-module. Given that we want to find short vectors, and our notion of shortness was just the normal Euclidean norm, we can embed this kernel into \mathbb{R}^{m} trivially, and have found a lattice. In fact, we have found the lattice, since with a good basis we could find the vector (s_0, e_0) closest to (s', e') in the kernel lattice, which means their difference would be short, and indeed it would be (s, e) (even if it was not, what the only property for the decryption algorithm to work is the s and e are short, so it would just decrypt).
Smith unfortunately gives us a very large special solution and kernel basis vectors that very much are a bad basis of the kernel, which means that we won’t be able to find this closest vector, and this property gives Learning With Errors its security.
Closing Remarks
Since we have encrypted a single bit, if we used the scheme as is, it would be incredibly wordy, since we would need to repeat all of this 128 times (or more) to actually transmit a key. Kyber (or ML-KEM in NIST terms) uses some trickery to both make keys and ciphertexts smaller and operations faster, but I won’t go into them in this blog post.
Also, just like textbook RSA, the algorithm I presented here would not be secure in interactive settings, and needs additional modifications to ensure that we cannot extract the secret key by sending several related messages and observing whether the decrypting party use the same or a different key. But this too would need a separate blog post.





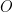





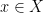

































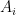














for enough
.
and factorize it.

![S = \text{Spec} K[X]/((X, X)_i)](https://s0.wp.com/latex.php?latex=S+%3D+%5Ctext%7BSpec%7D+K%5BX%5D%2F%28%28X%2C+X%29_i%29&bg=ffffff&fg=000&s=0&c=20201002)







 , i.e. a function that everybody can evaluate efficiently at any point
, i.e. a function that everybody can evaluate efficiently at any point  , computing
, computing 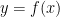 , but where, given
, but where, given  , finding an
, finding an  is difficult, unless one knowns some extra information
is difficult, unless one knowns some extra information  , in which case it is easy. In other words, there is a function
, in which case it is easy. In other words, there is a function  that is easy to evaluate such that
that is easy to evaluate such that  .
. is the value
is the value  . The most prominent example of a signature scheme using this paradigm is RSA-PKCS1, where modular exponentiation is the one-way function, and the factorization of the modulus is the trapdoor information making it reversible.
. The most prominent example of a signature scheme using this paradigm is RSA-PKCS1, where modular exponentiation is the one-way function, and the factorization of the modulus is the trapdoor information making it reversible. . Note that the second sum starts at
. Note that the second sum starts at  , since we are operating over commutative fields, so we can always reorder things so that
, since we are operating over commutative fields, so we can always reorder things so that  . This will be useful later. Also note that we only use a homogenous polynomial, i.e. a polynomial without linear or constant components. This is both a simplification and something that does not matter in practice, as you could always homogenize the polynomial.
. This will be useful later. Also note that we only use a homogenous polynomial, i.e. a polynomial without linear or constant components. This is both a simplification and something that does not matter in practice, as you could always homogenize the polynomial.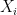 into a vector
into a vector  , then
, then  will evaluate to the exact same polynomial as above, with
will evaluate to the exact same polynomial as above, with  being a triangular matrix. We can shift around the coefficients of
being a triangular matrix. We can shift around the coefficients of  remains the same (if the characteristic is not equal to two, which will be a common caveat in this post).
remains the same (if the characteristic is not equal to two, which will be a common caveat in this post). , a bilinear form, i.e. a function that is linear in both arguments and evaluates to a single field element. In other words, given a bilinear form
, a bilinear form, i.e. a function that is linear in both arguments and evaluates to a single field element. In other words, given a bilinear form  , we get the associated quadratic form by evaluating at the diagonal. Note that for the bilinear form, the order very much matters, since
, we get the associated quadratic form by evaluating at the diagonal. Note that for the bilinear form, the order very much matters, since  , so in this case, we can no longer simply assume upper triangular matrices. In fact, usually, when studying quadratic forms, mathematicians restrict themselves to symmetric bilinear forms as the associated bilinear forms, i.e. forms with
, so in this case, we can no longer simply assume upper triangular matrices. In fact, usually, when studying quadratic forms, mathematicians restrict themselves to symmetric bilinear forms as the associated bilinear forms, i.e. forms with  , corresponding to symmetric matrices
, corresponding to symmetric matrices  . Super nice for computers, since a single byte corresponds to a field element, but really inconvenient for the more theoretical analysis. We can mostly ignore this, but keep in mind that pretty much everything that uses bilinear forms might have an unwritten asterisk that goes into unreasonable detail about the situation in characteristic 2.
. Super nice for computers, since a single byte corresponds to a field element, but really inconvenient for the more theoretical analysis. We can mostly ignore this, but keep in mind that pretty much everything that uses bilinear forms might have an unwritten asterisk that goes into unreasonable detail about the situation in characteristic 2. . A signature of a message
. A signature of a message  , with
, with  some salt, such that
some salt, such that  .
. , with
, with 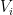 being a symmetric
being a symmetric  matrix, and
matrix, and  being a
being a  matrix. Written in this block fashion, it makes sense to distinguish the first
matrix. Written in this block fashion, it makes sense to distinguish the first  , which allows us to fully write down the private key and the signing algorithm:
, which allows us to fully write down the private key and the signing algorithm: . To sign, we first compute the hash of the salted message, chose random values for the vinegar variables, giving us
. To sign, we first compute the hash of the salted message, chose random values for the vinegar variables, giving us  as preliminary signature, leaving variables for the last m coefficients. We then compute
as preliminary signature, leaving variables for the last m coefficients. We then compute  , giving us
, giving us  . Since
. Since  , we now know that
, we now know that  , so
, so  is our signature.
is our signature.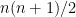 message signature pairs, but UOV is an endless pit of funny properties, so here we can discuss how to construct amusing public keys, such as, for example,
message signature pairs, but UOV is an endless pit of funny properties, so here we can discuss how to construct amusing public keys, such as, for example,  , so having a 0 in this position means that there are m linear independent vectors which, when put into the bilinear form in both positions, will evaluate to 0. So to get rid of the basis, we need an m-dimensional subvectorspace
, so having a 0 in this position means that there are m linear independent vectors which, when put into the bilinear form in both positions, will evaluate to 0. So to get rid of the basis, we need an m-dimensional subvectorspace  for i from 1 to m. It is this subvectorspace which makes up the private key. Since it corresponds to the last m variables when choosing a basis, it makes sense to call this the oil space, containing vectors consisting of only nonzero oil variables above.
for i from 1 to m. It is this subvectorspace which makes up the private key. Since it corresponds to the last m variables when choosing a basis, it makes sense to call this the oil space, containing vectors consisting of only nonzero oil variables above.  . Thankfully, there are tons of such vector spaces, and, as it will turn out later that the choice of vinegar space does not matter at all.
. Thankfully, there are tons of such vector spaces, and, as it will turn out later that the choice of vinegar space does not matter at all. , with
, with  . So we know that
. So we know that  , given the property of our bilinear forms. Choosing
, given the property of our bilinear forms. Choosing  randomly, we again get a linear equation per bilinear form to compute
randomly, we again get a linear equation per bilinear form to compute  , and in particular, if
, and in particular, if  is not very unluckily chosen, there is now only one
is not very unluckily chosen, there is now only one  has full rank. But then there is exactly one oil vector that solves for a particular right hand side, and that oil vector again does not depend on the basis we use for the oil space, just on the fact that it is in this oil space. So we can also chose the basis of the oil space basis as convenient. Note that, different from the vinegar space, this is not true for the oil space itself, which we had to secretly determine and now have no way of changing, just its basis.
has full rank. But then there is exactly one oil vector that solves for a particular right hand side, and that oil vector again does not depend on the basis we use for the oil space, just on the fact that it is in this oil space. So we can also chose the basis of the oil space basis as convenient. Note that, different from the vinegar space, this is not true for the oil space itself, which we had to secretly determine and now have no way of changing, just its basis. dimensional sub space and
dimensional sub space and  , with
, with 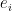 being the m dimensional unit vectors. All in all, this means our base change matrix now looks like this:
being the m dimensional unit vectors. All in all, this means our base change matrix now looks like this:  . Applying this base change to our public key as above, we get
. Applying this base change to our public key as above, we get  . So in order for the form to have the required shape, we need only that
. So in order for the form to have the required shape, we need only that  .
. block of the m quadratic forms. Which means that the rest of the public matrices can be chosen at random. The UOV competition entry cleverly uses this to make the public key much smaller, from
block of the m quadratic forms. Which means that the rest of the public matrices can be chosen at random. The UOV competition entry cleverly uses this to make the public key much smaller, from  bytes for the expanded public keys, to
bytes for the expanded public keys, to  bytes for the compressed public key, using the 16 extra bytes as a seed to input into an XOF, to generate
bytes for the compressed public key, using the 16 extra bytes as a seed to input into an XOF, to generate 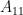 and
and 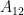 . I, in turn, can use this property to keep the public key large, but hide amusing message in them, like the aforementioned python script.
. I, in turn, can use this property to keep the public key large, but hide amusing message in them, like the aforementioned python script.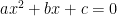 is
is  . In fact, in German high school, we called this formula the “midnight formula” on account that you should be able to recite it without hesitation if your math teacher wakes you up at midnight and asks you how to solve quadratic equations. This approach is called “solving by radicals”. It solves a polynomial equation by expressing the roots of the polynomial with field operations and a special function
. In fact, in German high school, we called this formula the “midnight formula” on account that you should be able to recite it without hesitation if your math teacher wakes you up at midnight and asks you how to solve quadratic equations. This approach is called “solving by radicals”. It solves a polynomial equation by expressing the roots of the polynomial with field operations and a special function ![\sqrt[n]{a}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bn%5D%7Ba%7D&bg=ffffff&fg=000&s=0&c=20201002) , which returns the single positive real solution of
, which returns the single positive real solution of  .
. ) is a problem of polynomial complexity, so there are efficient algorithms for computing the factorization, and by extend finding the rational solutions, of any univariate polynomial. And if you are a German high school student, after reading this section, you are officially allowed to answer with “it’s complicated”, roll over, and get a good night’s rest when your teacher wakes you in the middle of the night.
) is a problem of polynomial complexity, so there are efficient algorithms for computing the factorization, and by extend finding the rational solutions, of any univariate polynomial. And if you are a German high school student, after reading this section, you are officially allowed to answer with “it’s complicated”, roll over, and get a good night’s rest when your teacher wakes you in the middle of the night. are a total well-order, i.e. all monomials compare with each other through divisibility, and there is a smallest monomial (1), the same is not true for multivariate monomials: We still get a natural partial order via divisibility (e.g.
are a total well-order, i.e. all monomials compare with each other through divisibility, and there is a smallest monomial (1), the same is not true for multivariate monomials: We still get a natural partial order via divisibility (e.g.  is divisible by and ergo bigger than
is divisible by and ergo bigger than  ), not all monomials compare anymore, (e.g.
), not all monomials compare anymore, (e.g.  ). This quickly becomes a problem, for example division with remainder is no longer well-defined.
). This quickly becomes a problem, for example division with remainder is no longer well-defined. ). This is not the only possible order, and the choice of order will become very important later.
). This is not the only possible order, and the choice of order will become very important later. , with
, with 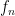 being univariate in
being univariate in  ,
,  being bivariate in
being bivariate in  , etc.
, etc. for the degree of the polynomials in the eventual basis, so yeah, it might be a while, and even just writing down the basis is not trivially possible. In fact, in practice it is the space complexity of Buchberger’s algorithm which destroys all hope of ever getting a solution far before the time complexity becomes relevant.
for the degree of the polynomials in the eventual basis, so yeah, it might be a while, and even just writing down the basis is not trivially possible. In fact, in practice it is the space complexity of Buchberger’s algorithm which destroys all hope of ever getting a solution far before the time complexity becomes relevant. , the field with 2 elements, but showing it for every other field is not substantially different.
, the field with 2 elements, but showing it for every other field is not substantially different. .
. . In other words, if we associate 0 with false and 1 with true, f is equal to NAND. Famously every boolean circuit can be expressed just by using NAND gates, and wiring up gates is the same as chaining function calls, which in turn is the same as substituting polynomials. This means every boolean expression equals one multivariate polynomial, with the degree being exponentially bounded by the circuit depth. In order to get back to a quadratic system of polynomials, we now introduce a new helper variable Y for each variable X that has a degree higher than a square, by adding the polynomial
. In other words, if we associate 0 with false and 1 with true, f is equal to NAND. Famously every boolean circuit can be expressed just by using NAND gates, and wiring up gates is the same as chaining function calls, which in turn is the same as substituting polynomials. This means every boolean expression equals one multivariate polynomial, with the degree being exponentially bounded by the circuit depth. In order to get back to a quadratic system of polynomials, we now introduce a new helper variable Y for each variable X that has a degree higher than a square, by adding the polynomial  to our system of polynomials. This allows us to halve the degree of the polynomial again, and taken together, we get a polynomial bounded system of quadratic equations (and if we do both steps together, we never explode the degree of the polynomials in illegitimate ways). This reduces SAT to MVQ. On the other hand, given a possible solution, verifying it can be done simply by evaluating quadratic polynomials, an operation that itself is polynomial in time, so MVQ is in NP, making it NP-complete.
to our system of polynomials. This allows us to halve the degree of the polynomial again, and taken together, we get a polynomial bounded system of quadratic equations (and if we do both steps together, we never explode the degree of the polynomials in illegitimate ways). This reduces SAT to MVQ. On the other hand, given a possible solution, verifying it can be done simply by evaluating quadratic polynomials, an operation that itself is polynomial in time, so MVQ is in NP, making it NP-complete.
 byte in size, with k = 2, 3, 4 being the security parameter. So if you have 4.6 KB to spare, and you want to do multiple encapsulation or decapsulation operations with the same key, or created an ephemeral key that you will immediately use to decapsulate with a roundtrip later, keep the fully expanded key in memory between operations and don’t unmarshal from the wire format every time.
byte in size, with k = 2, 3, 4 being the security parameter. So if you have 4.6 KB to spare, and you want to do multiple encapsulation or decapsulation operations with the same key, or created an ephemeral key that you will immediately use to decapsulate with a roundtrip later, keep the fully expanded key in memory between operations and don’t unmarshal from the wire format every time.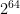 signatures are created. This restriction does not apply to ML-DSA, which provably does not degrade in security as more signatures are produced. This property allows for
signatures are created. This restriction does not apply to ML-DSA, which provably does not degrade in security as more signatures are produced. This property allows for  (notice the 4 instead of 2, to account for 32 bit integers instead of 16 bit integers), which means that ML-KEM-65 will need 30 KB of memory to cache its matrix when signing/verifying with the same key multiple times (16 KB for ML-DSA-44, 57 KB for ML-DSA-87).
(notice the 4 instead of 2, to account for 32 bit integers instead of 16 bit integers), which means that ML-KEM-65 will need 30 KB of memory to cache its matrix when signing/verifying with the same key multiple times (16 KB for ML-DSA-44, 57 KB for ML-DSA-87). that is not a perfect square (if
that is not a perfect square (if  , i.e. the primitive we are studying is a DRBG.
, i.e. the primitive we are studying is a DRBG. . This function clearly has a zero at
. This function clearly has a zero at  , which Newton’s method should find with quadratic convergence, assuming we started somewhere halfway decent.
, which Newton’s method should find with quadratic convergence, assuming we started somewhere halfway decent. .
.
 , which we would otherwise have to do if things didn’t cancel out this neatly.
, which we would otherwise have to do if things didn’t cancel out this neatly. with
with 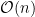 bits of space complexity.
bits of space complexity.![\alpha = \sqrt{a}-\lfloor\sqrt{a}\rfloor\in[0, 1]](https://s0.wp.com/latex.php?latex=%5Calpha+%3D+%5Csqrt%7Ba%7D-%5Clfloor%5Csqrt%7Ba%7D%5Crfloor%5Cin%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) of our
of our  , for some unknown integer
, for some unknown integer  . With that we have
. With that we have  , with both
, with both  being unknown integers. This isn’t looking very promising, one equation with two unknown variables, but then you realize that
being unknown integers. This isn’t looking very promising, one equation with two unknown variables, but then you realize that  is known to a precision high enough to contain more than enough information about both of these integers, if we can just tickle it out of it. It’s a linear equation (and in fact one of the goals of the substitution was to make it linear), and if you paid attention in one of my previous posts, a linear equation when the coefficients are integers is what lattices live for. We still need to manipulate it a bit further before we get to the actual lattice, though. First, we need a large number, let’s take something like
is known to a precision high enough to contain more than enough information about both of these integers, if we can just tickle it out of it. It’s a linear equation (and in fact one of the goals of the substitution was to make it linear), and if you paid attention in one of my previous posts, a linear equation when the coefficients are integers is what lattices live for. We still need to manipulate it a bit further before we get to the actual lattice, though. First, we need a large number, let’s take something like  . The main thing that matters here is not so much the value of
. The main thing that matters here is not so much the value of  itself, just that it is large enough for what comes next. And what comes next is a lattice, generated by the vectors
itself, just that it is large enough for what comes next. And what comes next is a lattice, generated by the vectors
 of the form
of the form  , with
, with  integers. In particular, the vector
integers. In particular, the vector  is a vector in our lattice, according to our previous calculations. Since
is a vector in our lattice, according to our previous calculations. Since  , given that both
, given that both  , i.e. only
, i.e. only  bit integers. If we vary
bit integers. If we vary  and with them
and with them 



