Introduction
It has come to my attention that people are wagering dinner invitations to anyone who can convince me to publicly state my opinions and reasonings on hybrid signatures. So in the interest of not having people starve, here is a blog post on this topic and the recent controversies surrounding it.
This is going to be a somewhat lengthy rant, so in case you want to check if you owe somebody dinner, here the takeaway upfront:
Using pure ML-DSA for keys that can be rotated (even if that rotation is under great pain), is perfectly fine. Using the ML-DSA44 parameter set for such keys is also fine. I won’t go as far as telling you that you should never use hybrid signatures, but I will say that hybrid signatures have a hidden cost that often makes them not worthwhile.
Why hybrid signatures are easy
The point of a hybrid construction (in this context, there are about 3 different things in cryptography called a hybrid) is to take two schemes and create a new scheme of the same type that is as secure as the more secure of the two schemes. In the case of KEMs, you need key derivation functions for this, and if you are not careful you run into weird edge cases with IND-CCA that make your combined scheme technically (although not practically) insecure. In the case of signatures, constructing a hybrid is dead simple: You simply concatenated the public keys and signatures of the component schemes, and add two ampersands between the two component verification calls. Done. You know have a EUF-CMA hybrid signature scheme.
Why hybrid signatures are difficult
It turns out that in practice, creating a hybrid signature scheme is surprisingly difficult, mostly because people cannot agree which color the two ampersands should have.
Part of this has to do with understanding what motivations people have to advocate for hybrid schemes. The first (and in my opinion only permissible) motivation is the one I outlined above, wanting to have a signature scheme that has the security of both component schemes. However, a second motivation that many people have is to use hybrids in the transition itself. The scheme level is in my opinion the wrong layer to switch schemes, but what people essentially are arguing for is to continue using their old classical keys, just now augmented with an additional PQC key.
The less harmful version of a similar motivation is to use two completely separate implementations of the schemes, for example using an HSM for the classical part and a software implementation for the PQC part. While this is less dangerous, it forces the implementation to be crossing several layers, again leading to the wish of being able to use the keys somewhat separably. And once keys are used separately, an attacker starts to be able to take a hybrid signature and rip it apart into a separate, valid signature, or take a non-hybrid signature and a broken secondary scheme and glue them together into a hybrid signature the signer has never signed.
This property is called separability, and our simple concatenation scheme is very much separable. So are pretty much all constructions, to varying degree. And that varying degree allows for discussion of the color of ampersands. For example, we could introduce a domain separator into our hybrid scheme, and hope that that would make component signatures unusable. However, domain separators need to be chosen from a prefix-free set. And if you are only adding the domain separator to the hybrid, and not the already existing classical use, you run into the problem that the empty string is a prefix of every string, and as such your set of domain separators is very much not prefix-free.
Next, we have the issue of the context. Both ML-DSA and SLH-DSA have a context parameter in their specification, and if you are trying to describe a hybrid, you have to define around that, resulting in even more possible shades for your ampersands. You either ignore it and upset some people, or you retrofit it into the classical signature scheme and upset a bunch of other people. In either case, you are dealing with far more cryptography than you originally thought.
Next, we have our old friend, prehashing. ML-DSA with external-µ uses external µ, and with it a very specific construction using SHAKE256 as its compressing hash function, while, say, ECDSA-P256-SHA256 uses SHA256. Now you could sign µ with ECDSA, inventing ECDSA-P256-external-µ in the process, but that would be a different signature scheme and now you’ve upset the people who wanted to reuse HSMs. You can add yet another compressing hash function into the mix, and now you have something that starts to resemble the current LAMPS draft, arriving at a scheme that everybody hates the least.
This still leaves probably the biggest issue with hybrids: The combinatorical explosion. Given that you can combine any two schemes, you can create a lot of potential combinations. And people have created a lot of combinations.

This is an except of the aforementioned IETF signature combiner draft. 18 different combinations. Various different variants of RSA, and ECDSA combined with various different variants of ML-DSA. Some people want to match security levels, some people wanted to use a higher pqc security level, so both options go in. Some people wanted PKCS1, some people wanted PSS versions of RSA. So they go in. Some people wanted Brainpool curves, some people wanted Curve25519, some people wanted NIST curves. So they all go in. Rainbow ampersands for everyone!
This means implementers will now have to choose: Support all of the schemes? Probably not feasible. Support only some of them? Now you risk incompatibilities. It also means that regulators don’t have to choose: Don’t like the NIST curves? Just mandate the use of Curve25519, or better yet, Brainpool after all, it’s in the standard so surely everyone will support all of them, and systems of various compliance regimens will never interact with each other anyways, right?
All in all, the thing that makes hybrid signatures difficult is pretty much entirely due to social coordination reasons, and not technical reasons, but social coordination is a cost that cannot be neglected when looking at cryptographic primitives, and it has become clear that the social coordination costs of hybrid signatures is very high, much higher than many other standardization efforts have.
Are hybrid signatures schemes actually useful?
This brings us to the second question: Are hybrid signatures actually all that useful? After all, while the social coordination problem might be annoying, it is something that can usually be resolved, eventually at least. But here comes the kicker: Hybrid constructions are, by design, a temporary measure. So if the resolving of the social problems takes to long, it can result in the stable equilibrium point just moving past them entirely.
This brings us to a few important differences between key agreement schemes and signature schemes in practical deployments.
When it comes to key agreement, or more generally encryption schemes, your vulnerability begins when you create a ciphertext, and ends, well, never really. At some point your plaintext might only be of interest to historians, but don’t underestimate the lengths historians will go to in order to recover it. (I try to exclude them from my threat models, they are too scary).
For signatures on the other hand, your vulnerability begins and ends with your verifier starting and stopping to trust the public key. The bad news is that you don’t even need to create a signature to be potentially vulnerable, the good news is that your window of vulnerability is extremely finite. And even better yet: We have some methods to end the window of vulnerability early, by revoking the public key in question. Revocation is of course not without its problems, but even its theoretical existence can make us relax a lot more when it comes to novel cryptographic algorithms.
There are some keys that live virtually forever and can neither be revoked in an emergency, nor rotated in a normal key lifecycle management. These are keys such as firmware signing keys which are baked into silicon. At least on this mitigation aspect, those keys behave more like encryption keys (maybe sans the historian threat actors), and they need a separate analysis.
For all other keys, though, the time limit and revocation options mean that, opposed to encryption keys, the breakage of a signing key can be actively mitigated.
Signing keys differ from encryption keys in another important way: They are long lived. Where encryption keys are often ephemeral, there is no use case that would require an ephemeral signing key, that would not be better served with a cryptographic hash instead. After all, conceptually a signature scheme moves authentic channels through time, by using an existing authentic channel to transfer a public key which then can be used in the future to create a new authentic channel. If the channels existed at the same time, transfering a hash in the authentic channel would serve the same purpose.
The longer lifetime already increases compromise risks by completely classical means, so having robust rotation and revocation procedures in place for signing keys is already best practice.
Taken together, this means we have a rather large difference in threat model between signing keys and encryption keys: Where encryption keys should be hybrid, since there is no action possible if a break in the newer algorithm becomes known, a signing key can remediate this scenario.
Additionally, while an encryption key’s breakage is completely silent, in order to use a compromised signing key the attacker has to convince some endpoint to interact with the forgery they produced. This means, while still difficult to detect, signature keys being broken is detectable, especially if this type of breakage happens at scale.
This only leaves the question of how likely a break of ML-DSA is, and whether this break would likely happen in public or not.
ML-DSA mythbusting
A few months ago, somewhat similar circumstances led to me writing a blog post on ML-KEM mythbusting. Most of the answers in that blog equally apply to ML-DSA. Like ML-KEM, ML-DSA was created by a group of European researchers, was standardized under strict scrutiny of the international cryptographic community, and has a parameter space that is way too small to hide a NOBUS backdoor. While the entropy of the parameters (the calculation of which I leave as an exercise to the reader) is higher than that of ML-KEM, it still does not reach cryptographical relevance. I have included the parameter set below:

There is one thing where ML-KEM and ML-DSA differ: While ML-KEM uses the Fujisaki-Okamoto transform to create its KEM, and the changes to that transform was the one change that sparked some debate that I referred to in my mythbusting blog post, ML-DSA uses a variant of the Fiat-Shamir transform to construct its signature scheme. Fiat-Shamir requires the use of a nonce and is extremely sensitive to reuse. The nonce is used to mask the private key, which is otherwise part of the signature, and reusing a nonce leads to the same mask being used twice, leaking the key. A similar problem also occurs with ECDSA, which is technically not a Fiat-Shamir transform, but somewhat related. ECDSA is usually used with random nonces, relying on the random number generator at signing time to prevent nonce reuse. This has led to key compromises in the past, when the random number generator had trouble being random. For EdDSA (and deterministic ECDSA), the random number generator is instead replaced with a PRF, which uses the private key and the message to deterministically compute a nonce for a given message. This makes those schemes robust against random number generator failures at signing time, but, at least in the case of EdDSA, comes at the cost of a higher risk for fault attacks. As the nonce is computed from the private key and the message, but the challenge hash is computed from the public key and the message, any fault in the public key can lead to two different signatures being computed for the same nonce.
For ML-DSA, the designers went all out and put every mitigation into the algorithm that we are aware of. ML-DSA has randomness in its private key that it always uses to compute the nonce, but it will additionally accept external randomness, which reduces the chance of faults occurring. Additionally when computing the nonce and the challenge hash µ is used instead of the raw message, making it so that both nonce and signature depend on the public key, eliminating the potential faults that can break EdDSA. As a result, ML-DSA is substantially more robust against Fiat-Shamir related attacks than ECDSA or EdDSA are. Of course, if you manage to introduce a fault deep in the algorithm that leads to a reused nonce, ML-DSA will still fail, but the attack surface is substantially smaller. I will leave it as an exercise to the reader to determine the motivations of anyone who drags up Fiat-Shamir related attacks on ML-DSA as an argument against the algorithm, but stays quiet on the same attacks on, say, EdDSA.
 which is easy to evaluate in one direction, but require the private key to invert, and a hash function
which is easy to evaluate in one direction, but require the private key to invert, and a hash function  . A signature
. A signature  is then some value in the domain of
is then some value in the domain of  holds. We can see that this hash serves a crucial security purpose by recognizing that without it, we would trivially find an existential forgery: Just pick a random
holds. We can see that this hash serves a crucial security purpose by recognizing that without it, we would trivially find an existential forgery: Just pick a random  . Congratulations, you have forged a signature for
. Congratulations, you have forged a signature for 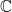 , the complex numbers). It is not possible to implement FN-DSA without floating points.
, the complex numbers). It is not possible to implement FN-DSA without floating points. with s and e short, we compute
with s and e short, we compute  with all for elements being short, and then set the public key to
with all for elements being short, and then set the public key to  . These two problems are closely related (they are both p-adic rational reconstruction problems, very visibly so in the case of NTRU where our public key is literal a rational number, rounded to one q-adic digit), with the main difference being that NTRU computes a full lattice basis, while LWE only computes a single short lattice vector.
. These two problems are closely related (they are both p-adic rational reconstruction problems, very visibly so in the case of NTRU where our public key is literal a rational number, rounded to one q-adic digit), with the main difference being that NTRU computes a full lattice basis, while LWE only computes a single short lattice vector. by computing
by computing  such that
such that  and
and  .
. and publishing
and publishing  as the signature (
as the signature (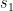 can be recomputed from these two values, and we need to verify that they are both small).
can be recomputed from these two values, and we need to verify that they are both small). , obeys a differential equation
, obeys a differential equation  . In other words,
. In other words, 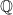 (such as adding the imaginary unit i to the rational numbers), and an order in such a number field is a generalization of the integers (such as adding the imaginary unit i to the integers, to obtain the number field order called the
(such as adding the imaginary unit i to the rational numbers), and an order in such a number field is a generalization of the integers (such as adding the imaginary unit i to the integers, to obtain the number field order called the  such that
such that  , which mainly boils down to describing the kernel, the solutions to
, which mainly boils down to describing the kernel, the solutions to  . For RLWE (or indeed, for NTRU), we need to switch to a number field order, which we mainly do by replacing the capital
. For RLWE (or indeed, for NTRU), we need to switch to a number field order, which we mainly do by replacing the capital  with a lower case
with a lower case  . We can, of course, without much consequence, switch the sign of the error term, and write
. We can, of course, without much consequence, switch the sign of the error term, and write  , for the lattice we need to reduce. With a slight reordering, this is equivalent to
, for the lattice we need to reduce. With a slight reordering, this is equivalent to  . Since
. Since  and
and  , a function
, a function  is said to hide the subgroup
is said to hide the subgroup  of
of  . The hidden subgroup problem is Abelian if the group in question is Abelian. This is a bit of a mouthful, so let’s look at a trivial example first, using
. The hidden subgroup problem is Abelian if the group in question is Abelian. This is a bit of a mouthful, so let’s look at a trivial example first, using 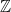 as our group and try to hide
as our group and try to hide  as a subgroup. A function would hide this subgroup if it has a different value on the cosets, for example, if the function was just the value of the integer modulo 3. For a slightly more interesting function, which actually meaningfully hides something, we can look at the world of variant Sudoko, where we often see the concept of a modular line or modular mirror or similar, which requires certain digits to have the same residue mod 3 (For example
as a subgroup. A function would hide this subgroup if it has a different value on the cosets, for example, if the function was just the value of the integer modulo 3. For a slightly more interesting function, which actually meaningfully hides something, we can look at the world of variant Sudoko, where we often see the concept of a modular line or modular mirror or similar, which requires certain digits to have the same residue mod 3 (For example  , where
, where  . Knowing this means we know very well how, at least in theory, any subgroup of an Abelian group looks like, which is going to make the next bits a bit easier to grasp in their generalities.
. Knowing this means we know very well how, at least in theory, any subgroup of an Abelian group looks like, which is going to make the next bits a bit easier to grasp in their generalities. , we are looking for
, we are looking for  such that
such that  . Instead of working with G as domain, we use two copies of
. Instead of working with G as domain, we use two copies of  , and define our function
, and define our function  as
as  . Since
. Since  , this is equal to
, this is equal to  , i.e. it’s a linear transform on
, i.e. it’s a linear transform on  followed by a discrete exponentiation.
followed by a discrete exponentiation. .
. .
. is
is  , from which we can recover n’s factors p and q easily. So how is order finding an Abelian Hidden Subgroup Problem? Just take a random element
, from which we can recover n’s factors p and q easily. So how is order finding an Abelian Hidden Subgroup Problem? Just take a random element  and define
and define  . This function has the same result exactly for all the multiples of the order of a, in other words it hides
. This function has the same result exactly for all the multiples of the order of a, in other words it hides  as a subgroup of
as a subgroup of 
 , and it has to be at least double the rank times degree, and 3329 is literally the smallest prime that fits that bill))
, and it has to be at least double the rank times degree, and 3329 is literally the smallest prime that fits that bill)) . At this point, the attacker cannot really assume that they were observing a decapsulation failure anymore, as a whole range of other incredibly unlikely events, such as enough simultaneous bit flips due to cosmic radiation to evade error detection are far more likely. It is true that after the first decapsulation failure has been observed, the attacker has much more abilities to stack the deck in their favor, but to do so, you first need the first failure to occur, and there is not really any hope in doing so.
. At this point, the attacker cannot really assume that they were observing a decapsulation failure anymore, as a whole range of other incredibly unlikely events, such as enough simultaneous bit flips due to cosmic radiation to evade error detection are far more likely. It is true that after the first decapsulation failure has been observed, the attacker has much more abilities to stack the deck in their favor, but to do so, you first need the first failure to occur, and there is not really any hope in doing so.
 for RLWE is computed as
for RLWE is computed as  with
with 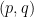 of number field integers that fulfill
of number field integers that fulfill  , and finds the closest lattice vector in this lattice to a special solution
, and finds the closest lattice vector in this lattice to a special solution  . The difference of this closest lattice vector from our special solution
. The difference of this closest lattice vector from our special solution  is by definition of closest lattice point, short, and is equal to the original secret (or at least equivalent in power to it). The security of RLWE comes from the fact that this closest vector computation is hard for a randomly chosen
is by definition of closest lattice point, short, and is equal to the original secret (or at least equivalent in power to it). The security of RLWE comes from the fact that this closest vector computation is hard for a randomly chosen 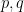 such that
such that  modulo the prime. To any external party, it would be impossible to distinguish this type of
modulo the prime. To any external party, it would be impossible to distinguish this type of 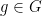 with some order
with some order  , so
, so  where
where  is the neutral element of the group. The we take our private key
is the neutral element of the group. The we take our private key  and compute our public key as
and compute our public key as  . We can now compute a shared secret with some other public key
. We can now compute a shared secret with some other public key  as
as  .
. . This map is a group homomorphism and is not necessarily injective. In fact, for finite groups, it is never injective. There is an old trick in algebra, where you can make any group homomorphism injective, by dividing the domain by its kernel. The kernel in question here is the ideal
. This map is a group homomorphism and is not necessarily injective. In fact, for finite groups, it is never injective. There is an old trick in algebra, where you can make any group homomorphism injective, by dividing the domain by its kernel. The kernel in question here is the ideal  of all multiples of our order
of all multiples of our order  is a sensible first step with no drawbacks, you don’t really get new keys by allowing all integers. The map is also not necessarily surjective, though. In fact, image of the map is exactly
is a sensible first step with no drawbacks, you don’t really get new keys by allowing all integers. The map is also not necessarily surjective, though. In fact, image of the map is exactly  , the subgroup of
, the subgroup of  (This is why we call
(This is why we call  . With that our private to public key map is not just a group homomorphism, but also injective and surjective, in other words, a group isomorphism.
. With that our private to public key map is not just a group homomorphism, but also injective and surjective, in other words, a group isomorphism. are the same thing, even if the clock uses Roman numerals. So simple relabeling of group elements should not count as a separate thing. In other words, we want to classify finite simple groups up to isomorphism.
are the same thing, even if the clock uses Roman numerals. So simple relabeling of group elements should not count as a separate thing. In other words, we want to classify finite simple groups up to isomorphism.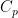 , the cyclic groups with prime order. Another such family are the alternating groups, from
, the cyclic groups with prime order. Another such family are the alternating groups, from 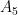 onwards. There are 16 more such infinite families, the others being said to be of “Lie type”. And then there are 26 groups that just, sort, of hang out by themselves. They are not part of an infinite family, they just exist, and there is no way to make them bigger or anything. The monster group mentioned above is the largest of them, and I totally did not chose it in the intro because it has a cool name and let’s me go on a tangent about sporadic groups.
onwards. There are 16 more such infinite families, the others being said to be of “Lie type”. And then there are 26 groups that just, sort, of hang out by themselves. They are not part of an infinite family, they just exist, and there is no way to make them bigger or anything. The monster group mentioned above is the largest of them, and I totally did not chose it in the intro because it has a cool name and let’s me go on a tangent about sporadic groups. there is a class
there is a class  of homomorphisms between
of homomorphisms between  and
and  . Homomorphisms are just that, elements of this class. We are generous enough to require there to be an identity homomorphism in
. Homomorphisms are just that, elements of this class. We are generous enough to require there to be an identity homomorphism in  and a composition operations, where the existence of
and a composition operations, where the existence of  and
and  gives you a homomorphism
gives you a homomorphism  , but that’s about it. In particular, we do not even necessarily require our objects to be sets. We definitely do not require our homomorphisms to be functions. In fact, just so that nobody gets any stupid ideas, when we don’t call them homomorphisms, we call them arrows. A category is really more like a directed graph. A graph that has so many vertices that they do not necessarily fit in a set any more, and where two vertices might have so many edges between them that they don’t fit either. This is why we said class above, a class is a collection of things that is potentially larger than any set. For example, there is a class of all sets, but there cannot be a set of all sets, because
, but that’s about it. In particular, we do not even necessarily require our objects to be sets. We definitely do not require our homomorphisms to be functions. In fact, just so that nobody gets any stupid ideas, when we don’t call them homomorphisms, we call them arrows. A category is really more like a directed graph. A graph that has so many vertices that they do not necessarily fit in a set any more, and where two vertices might have so many edges between them that they don’t fit either. This is why we said class above, a class is a collection of things that is potentially larger than any set. For example, there is a class of all sets, but there cannot be a set of all sets, because  is an object such that for any
is an object such that for any  ,
,  has exactly one element. A terminal object
has exactly one element. A terminal object  is the dual object, i.e. for every
is the dual object, i.e. for every  . If an object is both initial and terminal we call this object a zero object, and the unique homomorphism it has for a given
. If an object is both initial and terminal we call this object a zero object, and the unique homomorphism it has for a given 
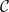 that we use as our base. We want to make some object
that we use as our base. We want to make some object  . So, if we don’t have elements, how can we describe the group axioms? Well the first one, associativity, is about multiplication. Multiplication is a map, mapping two elements of the group to one element, so we can just say that we require that map to be a homomorphism in
. So, if we don’t have elements, how can we describe the group axioms? Well the first one, associativity, is about multiplication. Multiplication is a map, mapping two elements of the group to one element, so we can just say that we require that map to be a homomorphism in  (Do not ask what
(Do not ask what  is if
is if  is the same as
is the same as  . This is due to the universal property thing that we do not talk about, but it gives us this canonical isomorphism, i.e. those two constructions are the same, and they are the same in some very obvious way. Now associativity is just saying that the multiplication morphism, applied twice in one order, is the same as the multiplication morphism, applied twice, in some other order, what you see in the screenshot as the first property. Similarly, commutativity is also just a statement on the multiplication morphism, with yet another canonical morphism, explaining the fourth, optional property.
. This is due to the universal property thing that we do not talk about, but it gives us this canonical isomorphism, i.e. those two constructions are the same, and they are the same in some very obvious way. Now associativity is just saying that the multiplication morphism, applied twice in one order, is the same as the multiplication morphism, applied twice, in some other order, what you see in the screenshot as the first property. Similarly, commutativity is also just a statement on the multiplication morphism, with yet another canonical morphism, explaining the fourth, optional property. and call it the neutral morphism. Note that 0 is the terminal object, not the initial object, so e is not necessarily unique. In fact, if we take the category of sets as our base (which will give us back the groups we know and love), the terminal object, as discussed above, is the singleton set. A map from the singleton set into a set can be seen as pointing at one specific element in our target set. To put differently, an element of
and call it the neutral morphism. Note that 0 is the terminal object, not the initial object, so e is not necessarily unique. In fact, if we take the category of sets as our base (which will give us back the groups we know and love), the terminal object, as discussed above, is the singleton set. A map from the singleton set into a set can be seen as pointing at one specific element in our target set. To put differently, an element of  in the category of sets is just an element of
in the category of sets is just an element of  , but without mentioning
, but without mentioning  , and instead phrase it as a series of maps. Let’s stay with
, and instead phrase it as a series of maps. Let’s stay with  , we want to make a statement about
, we want to make a statement about  , using the prefix notation instead of the more familiar infix. So we need to construct
, using the prefix notation instead of the more familiar infix. So we need to construct  , ideally starting from
, ideally starting from  . That’s not quite
. That’s not quite  . Now we can apply
. Now we can apply  and expect to end up at the same place. In other words
and expect to end up at the same place. In other words  . And suddenly, we have described what a neutral element does, without having, you know, elements.
. And suddenly, we have described what a neutral element does, without having, you know, elements. and nothing else. We still want something that behaves like a group, though, since the whole stuff with agreeing on keys and stuff fundamentally relied on there being some group things going on. We need a group object. But what is our category
and nothing else. We still want something that behaves like a group, though, since the whole stuff with agreeing on keys and stuff fundamentally relied on there being some group things going on. We need a group object. But what is our category  and the multiplicative group
and the multiplicative group  . The additive group would work for Diffie-Hellman, if it wasn’t for this very efficient algorithm that can solve the discrete log problem in this group, named “division”. The multiplicative group we set aside and get to in the next chapter. That leaves us with abelian varieties. Varieties have an important invariant, called the dimension. So what are the abelian varieties of dimension 1? Elliptic curves. And they work great. We could go to higher dimensions (and in fact people have explored this), but it turns out you don’t really get anything but headaches from that. They result in secure constructions, but point counting is hard, and you get these “special divisors” which make constant time programming a nightmare, and get nothing in return. So that is why elliptic curves, even though at first glance looking like a quite arbitrary and odd choice for a “group” are actually pretty much the only choice there is.
. The additive group would work for Diffie-Hellman, if it wasn’t for this very efficient algorithm that can solve the discrete log problem in this group, named “division”. The multiplicative group we set aside and get to in the next chapter. That leaves us with abelian varieties. Varieties have an important invariant, called the dimension. So what are the abelian varieties of dimension 1? Elliptic curves. And they work great. We could go to higher dimensions (and in fact people have explored this), but it turns out you don’t really get anything but headaches from that. They result in secure constructions, but point counting is hard, and you get these “special divisors” which make constant time programming a nightmare, and get nothing in return. So that is why elliptic curves, even though at first glance looking like a quite arbitrary and odd choice for a “group” are actually pretty much the only choice there is. , for an elliptic curve given by
, for an elliptic curve given by  . Two elliptic curves are isomorphic (over the algebraic closure) if and only if they have the same j invariant.
. Two elliptic curves are isomorphic (over the algebraic closure) if and only if they have the same j invariant. , if
, if 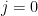 , we can use the curve
, we can use the curve  . For
. For  , we can use the curve
, we can use the curve  . For all other cases, we can just use
. For all other cases, we can just use  . You can check that this will have the right j invariant.
. You can check that this will have the right j invariant. . It kind of looks like an elliptic curve at first glance. Sure it’s not in Weierstraß form, but you can rectify that and give an isomorphic curve that has that form (I’m too lazy to do that right now). However, this is not an elliptic curve. In order for a curve to be elliptic, it needs to not have any singularities, and this curve has, …, well, here is a plot of it:
. It kind of looks like an elliptic curve at first glance. Sure it’s not in Weierstraß form, but you can rectify that and give an isomorphic curve that has that form (I’m too lazy to do that right now). However, this is not an elliptic curve. In order for a curve to be elliptic, it needs to not have any singularities, and this curve has, …, well, here is a plot of it:
 . And when you do that, you notice something strange. You can simplify the formula. It’s a bit on the lengthier side of algebra when doing it by hand the long way around, but very much doable. And when you simplify it, you notice that the points on the nodal curve (save for the singularity) can be described by a single non-zero field element, and that adding two points is the same as multiplying the corresponding field elements. In other words, this curve, the somewhat awkward reject elliptic curve, gives us the multiplicative group. Finite field Diffie-Hellman is also just Elliptic Curve Diffie-Hellman, just over a curve that accidentally twisted itself a bit. And we found that curve naturally, trying to hang out with its elliptic curve friends on the same moduli space (as opposed to the cuspial curve
. And when you do that, you notice something strange. You can simplify the formula. It’s a bit on the lengthier side of algebra when doing it by hand the long way around, but very much doable. And when you simplify it, you notice that the points on the nodal curve (save for the singularity) can be described by a single non-zero field element, and that adding two points is the same as multiplying the corresponding field elements. In other words, this curve, the somewhat awkward reject elliptic curve, gives us the multiplicative group. Finite field Diffie-Hellman is also just Elliptic Curve Diffie-Hellman, just over a curve that accidentally twisted itself a bit. And we found that curve naturally, trying to hang out with its elliptic curve friends on the same moduli space (as opposed to the cuspial curve  , with its way nastier singularity, which happens to give you the additive group instead, and does not hang out on this moduli space).
, with its way nastier singularity, which happens to give you the additive group instead, and does not hang out on this moduli space).

 such that the public key is
such that the public key is  . s and e have to be drawn from a specific distribution in order for the key to be secure, with the key generation algorithm describing how to do so, meaning that the seed enforces this specific distribution, which can not easily be proven to be case afterwards.
. s and e have to be drawn from a specific distribution in order for the key to be secure, with the key generation algorithm describing how to do so, meaning that the seed enforces this specific distribution, which can not easily be proven to be case afterwards. and signatures being a triple
and signatures being a triple  and expanded how this mathematical definition warps and bends when hitting reality. To understand the difference between performance in competition conditions and performance in real life, we need to again look at the code that would implement such a triple, starting at the same code snippet from the last blog post:
and expanded how this mathematical definition warps and bends when hitting reality. To understand the difference between performance in competition conditions and performance in real life, we need to again look at the code that would implement such a triple, starting at the same code snippet from the last blog post:
 , which have the property that there exists a subspace
, which have the property that there exists a subspace  such that
such that  for all
for all  . This subspace
. This subspace 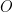 is the private key we are looking for. The attack in question is a key recovery attack working with the public key only, so we don’t really need to repeat how signing works, and we will focus solely on how to recover this subspace given the bilinear forms, with Part II discussing the signature scheme.
is the private key we are looking for. The attack in question is a key recovery attack working with the public key only, so we don’t really need to repeat how signing works, and we will focus solely on how to recover this subspace given the bilinear forms, with Part II discussing the signature scheme. there is at least one vector
there is at least one vector  such that
such that  . If you look at the matrix defining the bilinear form, this is equivalent of saying that this matrix has full rank.
. If you look at the matrix defining the bilinear form, this is equivalent of saying that this matrix has full rank. for this dual vector space.
for this dual vector space. and an element
and an element 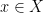 , we can look at the linear form
, we can look at the linear form  .
. , we know that
, we know that  as well, since the linear form 0 is defined by being 0 for all vectors in the vector space, and linearity in the first argument means that
as well, since the linear form 0 is defined by being 0 for all vectors in the vector space, and linearity in the first argument means that  , so by definition of non-degeneracy it follows that
, so by definition of non-degeneracy it follows that  is linear independent, then
is linear independent, then  is linear independent as well. This proves the statement I made above of finite dimensional vector spaces having the same dimension as their dual, and means that every non-degenerate bilinear form gives us a way of mapping column vectors to row vectors. This might seem like a lot of work for literally just turning a page 90 degrees, but as I said, quantum physicists still pay the price for thinking they could turn papers better all by themselves.
is linear independent as well. This proves the statement I made above of finite dimensional vector spaces having the same dimension as their dual, and means that every non-degenerate bilinear form gives us a way of mapping column vectors to row vectors. This might seem like a lot of work for literally just turning a page 90 degrees, but as I said, quantum physicists still pay the price for thinking they could turn papers better all by themselves.  are called orthogonal if
are called orthogonal if  . For a subvectorspace
. For a subvectorspace  we define
we define  . With this definition, we can rephrase the trapdoor of our bilinear forms as there being a subspace
. With this definition, we can rephrase the trapdoor of our bilinear forms as there being a subspace  such that
such that  . Basically, a subspace that is perpendicular to itself in all bilinear forms of the public key.
. Basically, a subspace that is perpendicular to itself in all bilinear forms of the public key. , and a subvectorspace
, and a subvectorspace  , we have
, we have  . To see this, take a basis of
. To see this, take a basis of  . For every basis vector
. For every basis vector  , we again look at the linear form
, we again look at the linear form  . This gives us
. This gives us  many linearly independent linear forms, all of which vanishing on
many linearly independent linear forms, all of which vanishing on  . We can consider these forms as a linear function
. We can consider these forms as a linear function  , and since they are linear independent, we know that this linear function has full rank. Vanishing on all forms makes
, and since they are linear independent, we know that this linear function has full rank. Vanishing on all forms makes  -dimensional vector space
-dimensional vector space  , i.e. there are as many oil vectors as there are vinegar vectors, and everything is “balanced”. We also have a secret,
, i.e. there are as many oil vectors as there are vinegar vectors, and everything is “balanced”. We also have a secret,  for all
for all  , as discussed above. One thing to note here is that
, as discussed above. One thing to note here is that  , so in this balanced case, and only in this balanced case, we further get
, so in this balanced case, and only in this balanced case, we further get  , since a subvectorspace that has the same dimension as the space is equal to the space.
, since a subvectorspace that has the same dimension as the space is equal to the space. and
and  there is exactly one linear function
there is exactly one linear function  such that
such that  for all
for all  is the map given by this base change. More concretely, if
is the map given by this base change. More concretely, if 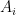 , i.e.
, i.e.  , then
, then  , since
, since  . If we hadn’t done all this work about bilinear forms, we would now need to add a two line proof that this is invariant under base change. I instead opted for writing several paragraphs worth of linear algebra, which, as surely we will all agree, is far preferable.
. If we hadn’t done all this work about bilinear forms, we would now need to add a two line proof that this is invariant under base change. I instead opted for writing several paragraphs worth of linear algebra, which, as surely we will all agree, is far preferable. is. We know that for any vector
is. We know that for any vector  ,
,  for all vectors
for all vectors  , so we know that
, so we know that  as well, so we know that
as well, so we know that  . But as pointed out above, in the balanced case
. But as pointed out above, in the balanced case  , so
, so  . This means that
. This means that  (technically, I have not proven equality, but that follows pretty easily by applying non-degeneracy again). This means
(technically, I have not proven equality, but that follows pretty easily by applying non-degeneracy again). This means  ,
,  linear functions sharing an eigenspace. So that common eigenspace is just
linear functions sharing an eigenspace. So that common eigenspace is just  for enough
for enough  .
.
 and factorize it.
and factorize it.![S = \text{Spec} K[X]/((X, X)_i)](https://s0.wp.com/latex.php?latex=S+%3D+%5Ctext%7BSpec%7D+K%5BX%5D%2F%28%28X%2C+X%29_i%29&bg=ffffff&fg=000&s=0&c=20201002) . Note that even though these polynomials are homogenous, we need to keep our
. Note that even though these polynomials are homogenous, we need to keep our  for now. This variety is a subvariety of
for now. This variety is a subvariety of  , and since it is given by m polynomials, it, assuming the polynomials are complete intersection, will be
, and since it is given by m polynomials, it, assuming the polynomials are complete intersection, will be  dimensional. For the non-geometers: This is similar how having m linear equations creates an n – m dimensional vector space, with “complete intersection” being the equivalent to things being linearly independent, only that stuff
dimensional. For the non-geometers: This is similar how having m linear equations creates an n – m dimensional vector space, with “complete intersection” being the equivalent to things being linearly independent, only that stuff  , since the quadratic forms, by definition, evaluate to 0 on
, since the quadratic forms, by definition, evaluate to 0 on 
 . Which makes
. Which makes 
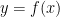 , but where, given
, but where, given  , finding an
, finding an  is difficult, unless one knowns some extra information
is difficult, unless one knowns some extra information  .
. . The most prominent example of a signature scheme using this paradigm is RSA-PKCS1, where modular exponentiation is the one-way function, and the factorization of the modulus is the trapdoor information making it reversible.
. The most prominent example of a signature scheme using this paradigm is RSA-PKCS1, where modular exponentiation is the one-way function, and the factorization of the modulus is the trapdoor information making it reversible. . Note that the second sum starts at
. Note that the second sum starts at  , since we are operating over commutative fields, so we can always reorder things so that
, since we are operating over commutative fields, so we can always reorder things so that  . This will be useful later. Also note that we only use a homogenous polynomial, i.e. a polynomial without linear or constant components. This is both a simplification and something that does not matter in practice, as you could always homogenize the polynomial.
. This will be useful later. Also note that we only use a homogenous polynomial, i.e. a polynomial without linear or constant components. This is both a simplification and something that does not matter in practice, as you could always homogenize the polynomial.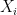 into a vector
into a vector  , then
, then  will evaluate to the exact same polynomial as above, with
will evaluate to the exact same polynomial as above, with  remains the same (if the characteristic is not equal to two, which will be a common caveat in this post).
remains the same (if the characteristic is not equal to two, which will be a common caveat in this post). , a bilinear form, i.e. a function that is linear in both arguments and evaluates to a single field element. In other words, given a bilinear form
, a bilinear form, i.e. a function that is linear in both arguments and evaluates to a single field element. In other words, given a bilinear form  , we get the associated quadratic form by evaluating at the diagonal. Note that for the bilinear form, the order very much matters, since
, we get the associated quadratic form by evaluating at the diagonal. Note that for the bilinear form, the order very much matters, since  , so in this case, we can no longer simply assume upper triangular matrices. In fact, usually, when studying quadratic forms, mathematicians restrict themselves to symmetric bilinear forms as the associated bilinear forms, i.e. forms with
, so in this case, we can no longer simply assume upper triangular matrices. In fact, usually, when studying quadratic forms, mathematicians restrict themselves to symmetric bilinear forms as the associated bilinear forms, i.e. forms with  , corresponding to symmetric matrices
, corresponding to symmetric matrices  . Super nice for computers, since a single byte corresponds to a field element, but really inconvenient for the more theoretical analysis. We can mostly ignore this, but keep in mind that pretty much everything that uses bilinear forms might have an unwritten asterisk that goes into unreasonable detail about the situation in characteristic 2.
. Super nice for computers, since a single byte corresponds to a field element, but really inconvenient for the more theoretical analysis. We can mostly ignore this, but keep in mind that pretty much everything that uses bilinear forms might have an unwritten asterisk that goes into unreasonable detail about the situation in characteristic 2. . A signature of a message
. A signature of a message  , with
, with  .
. , with
, with 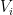 being a symmetric
being a symmetric  matrix, and
matrix, and  being a
being a  matrix. Written in this block fashion, it makes sense to distinguish the first
matrix. Written in this block fashion, it makes sense to distinguish the first  , which allows us to fully write down the private key and the signing algorithm:
, which allows us to fully write down the private key and the signing algorithm: . To sign, we first compute the hash of the salted message, chose random values for the vinegar variables, giving us
. To sign, we first compute the hash of the salted message, chose random values for the vinegar variables, giving us  as preliminary signature, leaving variables for the last m coefficients. We then compute
as preliminary signature, leaving variables for the last m coefficients. We then compute  , giving us
, giving us  . Since
. Since  , we now know that
, we now know that  , so
, so  is our signature.
is our signature.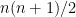 message signature pairs, but UOV is an endless pit of funny properties, so here we can discuss how to construct amusing public keys, such as, for example,
message signature pairs, but UOV is an endless pit of funny properties, so here we can discuss how to construct amusing public keys, such as, for example,  , so having a 0 in this position means that there are m linear independent vectors which, when put into the bilinear form in both positions, will evaluate to 0. So to get rid of the basis, we need an m-dimensional subvectorspace
, so having a 0 in this position means that there are m linear independent vectors which, when put into the bilinear form in both positions, will evaluate to 0. So to get rid of the basis, we need an m-dimensional subvectorspace  for i from 1 to m. It is this subvectorspace which makes up the private key. Since it corresponds to the last m variables when choosing a basis, it makes sense to call this the oil space, containing vectors consisting of only nonzero oil variables above.
for i from 1 to m. It is this subvectorspace which makes up the private key. Since it corresponds to the last m variables when choosing a basis, it makes sense to call this the oil space, containing vectors consisting of only nonzero oil variables above.  . Thankfully, there are tons of such vector spaces, and, as it will turn out later that the choice of vinegar space does not matter at all.
. Thankfully, there are tons of such vector spaces, and, as it will turn out later that the choice of vinegar space does not matter at all. , with
, with  . So we know that
. So we know that  , given the property of our bilinear forms. Choosing
, given the property of our bilinear forms. Choosing  randomly, we again get a linear equation per bilinear form to compute
randomly, we again get a linear equation per bilinear form to compute  , and in particular, if
, and in particular, if  is not very unluckily chosen, there is now only one
is not very unluckily chosen, there is now only one  has full rank. But then there is exactly one oil vector that solves for a particular right hand side, and that oil vector again does not depend on the basis we use for the oil space, just on the fact that it is in this oil space. So we can also chose the basis of the oil space basis as convenient. Note that, different from the vinegar space, this is not true for the oil space itself, which we had to secretly determine and now have no way of changing, just its basis.
has full rank. But then there is exactly one oil vector that solves for a particular right hand side, and that oil vector again does not depend on the basis we use for the oil space, just on the fact that it is in this oil space. So we can also chose the basis of the oil space basis as convenient. Note that, different from the vinegar space, this is not true for the oil space itself, which we had to secretly determine and now have no way of changing, just its basis. dimensional sub space and
dimensional sub space and  , with
, with 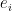 being the m dimensional unit vectors. All in all, this means our base change matrix now looks like this:
being the m dimensional unit vectors. All in all, this means our base change matrix now looks like this:  . Applying this base change to our public key as above, we get
. Applying this base change to our public key as above, we get  . So in order for the form to have the required shape, we need only that
. So in order for the form to have the required shape, we need only that  .
. block of the m quadratic forms. Which means that the rest of the public matrices can be chosen at random. The UOV competition entry cleverly uses this to make the public key much smaller, from
block of the m quadratic forms. Which means that the rest of the public matrices can be chosen at random. The UOV competition entry cleverly uses this to make the public key much smaller, from  bytes for the expanded public keys, to
bytes for the expanded public keys, to  bytes for the compressed public key, using the 16 extra bytes as a seed to input into an XOF, to generate
bytes for the compressed public key, using the 16 extra bytes as a seed to input into an XOF, to generate 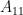 and
and 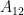 . I, in turn, can use this property to keep the public key large, but hide amusing message in them, like the aforementioned python script.
. I, in turn, can use this property to keep the public key large, but hide amusing message in them, like the aforementioned python script.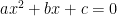 is
is  . In fact, in German high school, we called this formula the “midnight formula” on account that you should be able to recite it without hesitation if your math teacher wakes you up at midnight and asks you how to solve quadratic equations. This approach is called “solving by radicals”. It solves a polynomial equation by expressing the roots of the polynomial with field operations and a special function
. In fact, in German high school, we called this formula the “midnight formula” on account that you should be able to recite it without hesitation if your math teacher wakes you up at midnight and asks you how to solve quadratic equations. This approach is called “solving by radicals”. It solves a polynomial equation by expressing the roots of the polynomial with field operations and a special function ![\sqrt[n]{a}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bn%5D%7Ba%7D&bg=ffffff&fg=000&s=0&c=20201002) , which returns the single positive real solution of
, which returns the single positive real solution of  .
. ) is a problem of polynomial complexity, so there are efficient algorithms for computing the factorization, and by extend finding the rational solutions, of any univariate polynomial. And if you are a German high school student, after reading this section, you are officially allowed to answer with “it’s complicated”, roll over, and get a good night’s rest when your teacher wakes you in the middle of the night.
) is a problem of polynomial complexity, so there are efficient algorithms for computing the factorization, and by extend finding the rational solutions, of any univariate polynomial. And if you are a German high school student, after reading this section, you are officially allowed to answer with “it’s complicated”, roll over, and get a good night’s rest when your teacher wakes you in the middle of the night. are a total well-order, i.e. all monomials compare with each other through divisibility, and there is a smallest monomial (1), the same is not true for multivariate monomials: We still get a natural partial order via divisibility (e.g.
are a total well-order, i.e. all monomials compare with each other through divisibility, and there is a smallest monomial (1), the same is not true for multivariate monomials: We still get a natural partial order via divisibility (e.g.  is divisible by and ergo bigger than
is divisible by and ergo bigger than  ), not all monomials compare anymore, (e.g.
), not all monomials compare anymore, (e.g.  ). This quickly becomes a problem, for example division with remainder is no longer well-defined.
). This quickly becomes a problem, for example division with remainder is no longer well-defined. ). This is not the only possible order, and the choice of order will become very important later.
). This is not the only possible order, and the choice of order will become very important later. , with
, with 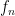 being univariate in
being univariate in  ,
,  being bivariate in
being bivariate in  , etc.
, etc. for the degree of the polynomials in the eventual basis, so yeah, it might be a while, and even just writing down the basis is not trivially possible. In fact, in practice it is the space complexity of Buchberger’s algorithm which destroys all hope of ever getting a solution far before the time complexity becomes relevant.
for the degree of the polynomials in the eventual basis, so yeah, it might be a while, and even just writing down the basis is not trivially possible. In fact, in practice it is the space complexity of Buchberger’s algorithm which destroys all hope of ever getting a solution far before the time complexity becomes relevant. , the field with 2 elements, but showing it for every other field is not substantially different.
, the field with 2 elements, but showing it for every other field is not substantially different. .
. . In other words, if we associate 0 with false and 1 with true, f is equal to NAND. Famously every boolean circuit can be expressed just by using NAND gates, and wiring up gates is the same as chaining function calls, which in turn is the same as substituting polynomials. This means every boolean expression equals one multivariate polynomial, with the degree being exponentially bounded by the circuit depth. In order to get back to a quadratic system of polynomials, we now introduce a new helper variable Y for each variable X that has a degree higher than a square, by adding the polynomial
. In other words, if we associate 0 with false and 1 with true, f is equal to NAND. Famously every boolean circuit can be expressed just by using NAND gates, and wiring up gates is the same as chaining function calls, which in turn is the same as substituting polynomials. This means every boolean expression equals one multivariate polynomial, with the degree being exponentially bounded by the circuit depth. In order to get back to a quadratic system of polynomials, we now introduce a new helper variable Y for each variable X that has a degree higher than a square, by adding the polynomial  to our system of polynomials. This allows us to halve the degree of the polynomial again, and taken together, we get a polynomial bounded system of quadratic equations (and if we do both steps together, we never explode the degree of the polynomials in illegitimate ways). This reduces SAT to MVQ. On the other hand, given a possible solution, verifying it can be done simply by evaluating quadratic polynomials, an operation that itself is polynomial in time, so MVQ is in NP, making it NP-complete.
to our system of polynomials. This allows us to halve the degree of the polynomial again, and taken together, we get a polynomial bounded system of quadratic equations (and if we do both steps together, we never explode the degree of the polynomials in illegitimate ways). This reduces SAT to MVQ. On the other hand, given a possible solution, verifying it can be done simply by evaluating quadratic polynomials, an operation that itself is polynomial in time, so MVQ is in NP, making it NP-complete. (Key Generation)
(Key Generation) (Signing algorithm)
(Signing algorithm) (Verification algorithm)
(Verification algorithm)