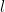A while ago, I was bored and wrote a Twitter post on how to find an integer if you only know the fractional part of its square root. My Twitter is private these days, and lies unused, but I still get questions about this topic from time to time, so I decided to put it into a blog post on here.
Why would one care about reconstructing an integer from the fractional part of its square root you might ask? It turns out there is some crank out there who claims that this can serve as the basis for his brilliant crypto system, so showing that this reconstruction is possible is the same as a key recovery attack.
Computing Square Roots
As usual with crank cryptography, the official documents are very light on actual description of the algorithm, so we will have to nail down the definitions first before we can actually attack the cryptosystem.
From what can be inferred from the documents, we first select a secret -bit integer that is not a perfect square (if is a perfect square the attack won’t work, but the algorithm will only produce zeroes, so it is trivially distinguishable). We then produce a “random” bitstream by looking at the digits of , i.e. the primitive we are studying is a DRBG.
Before we look at the security of this algorithm, lets first take a quick glance at how it otherwise works for a DRBG. The best algorithm to compute a square root is using Newton’s method to first compute the inverse square root, and then recover the square root via multiplication with the number itself. In other words, apply Newton’s method to the function . This function clearly has a zero at , which Newton’s method should find with quadratic convergence, assuming we started somewhere halfway decent.
For Newton’s method we need to first compute the derivative of our function, which is just .
Newton’s iteration then gives us:
Now we can see why we prefer to compute the inverse square root with the iteration: The formula happens to only ever divide by 2, so it is far cheaper then having to divide by , which we would otherwise have to do if things didn’t cancel out this neatly.
Quadratic convergence means we roughly double the number of correct digits each iteration step, but looking at our iteration step, we need to multiply several -bit precision numbers, so the total time complexity of this algorithm should be with bits of space complexity.
This is abysmal. A DRBG should have linear time complexity and constant space complexity, i.e. the cost of producing an extra bit of randomness should not depend on how much randomness was previously created. It seems like even our crank caught wind of that, because he used this generator just to seed a Blum-Blum-Shub generator, which, while one of the slowest DRBGs we have, has linear time complexity and constant space complexity. You can also add a backdoor to it, which I guess is a property you can have in a DRBG, if you like it.
Lattices enter Stage left
With the ranting about how badly this DRBG performs aside, to the main piece of this article, how to break it. We will use a well-known technique to tackle Diophantine equations with some lattice math for this.
For this, let’s get some -bit stream of of our -bit integer . In other words , for some unknown integer . Let’s set . With that we have , with both and being unknown integers. This isn’t looking very promising, one equation with two unknown variables, but then you realize that is known to a precision high enough to contain more than enough information about both of these integers, if we can just tickle it out of it. It’s a linear equation (and in fact one of the goals of the substitution was to make it linear), and if you paid attention in one of my previous posts, a linear equation when the coefficients are integers is what lattices live for. We still need to manipulate it a bit further before we get to the actual lattice, though. First, we need a large number, let’s take something like . The main thing that matters here is not so much the value of itself, just that it is large enough for what comes next. And what comes next is a lattice, generated by the vectors
In other words, the elements of our lattice are the vectors of of the form , with integers. In particular, the vector is a vector in our lattice, according to our previous calculations. Since is so large, this vector is fairly close to , given that both and are roughly , i.e. only bit integers. If we vary or though, we either have to make them very large, or we will never get as close in the first coordinate, as we carefully balanced things so that our linear equation works out.
In other words, if we find the lattice vector closest to , we have found our integers and with them .
But wait, I hear you say, isn’t that the Closest Vector Problem (CVP), known for being hard to compute. Well indeed it is. And it is hard to compute. For higher dimensional lattices. For a rank 2 lattice embedded in three dimensions, it’s not. You simply reduce the lattice basis above, express in this basis, round the coefficients to integers, and, as by magic, the coefficients will be the unknown integers. I’ve implemented this algorithm here, and here is a sample output:
Lattice reduction for two dimensional lattices is incredibly fast, resulting in an algorithm that is nearly as fast to break as it is to compute in the first place. The author of the algorithm suggested a hardening technique of varying the offset used, i.e. discarding some of the keystream. This of course doesn’t do anything, as the attack is fast enough, and the computation of the keystream is slow enough, that you can simply bruteforce all possible starting points, changing by a power of 2 as necessary to account for the discarded bits.
While this algorithm is obviously bogus for cryptographic purposes, the general technique for solving Diophantine equations with lattices is a useful tool to understand and study, similar techniques are for example used in Coppersmith’s attack on RSA with small exponents and are valuable to understand for anyone with an interest in discrete mathematics.
It’s now been several times that I had a conversation with some security folks that went something like this:
Them: “I wished this lattice stuff was easier, like RSA, I tried to read up on it but it was just so complex” Me: “I think RSA is actually a bit more complicated than Learning With Errors, the didatics on it are just not as far along” Them: *Pressing X to doubt* Me: “Fine, I’ll explain it, against my will. I am just going to note here that I am basically forced into this and derive no joy whatsoever from explaining lattice cryptography.”
So after having done that a few times, I figured I should put some of it into a more scalable, written form.
Prerequisites: A bit of Modular Arithmetic and a bit of Linear Algebra.
So what on Earth is a lattice?
A lattice is a free, finitely generated \mathbb{Z}-module usually embedded into a finite dimensional real vector space.
That’s a bit of a mouthful, so let’s break that down a bit.
The term module is just mathematicians being fancy and using a different word for “vector space, but over a ring” (In case you don’t know what a ring is, for this blog post, just replace that term with \mathbb{Z}, the integers. It’s a numbery thing where you can add, subtract, and multiply, but not necessarily divide. In case you don’t remember vector spaces, it’s where vectors live. You can add vectors, there is a zero vector, and you can multiply vectors with elements of the base ring/field to scale them).
Finitely generated means that there is a finite number of elements that generates it, in other words every element x in our module can be written as x = \sum_{i=1}^n a_i g_i, with a_i \in \mathbb{Z} and g_i being our finite set of generators.
This leaves us with free. A module is free, when it actually behaves like a vector space and doesn’t do any weird ring shit. Modules love doing weird ring shit, so this qualifier is unfortunately very necessary. More formally, it means that our module has a basis, i.e. that we can choose the g_i so that the sum above is unique. In that case, any such set will have the same length, which we call the rank of the module, because calling it the dimension would make too much sense and we can rewrite the module to be \mathbb{Z}^n. In other words, for any ring R all free, finitely generated R-modules are isomorphic to R^n.
So we have some integer vectors, and we want to embed them into a real vector space. To avoid some technicalities, I will only talk about so called full rank lattices, where the lattice rank is the same as the dimension of the vector space. I will also not go into the technical definition of embedding, it’s a fairly decent word as math words go and means pretty much that, the lattice is placed inside the vector space.
One thing to note is that there is more than one way to embed \mathbb{Z}^n into \mathbb{R}^n. Let’s take n=2 as example, so we can draw some pictures.
The lattice \left\langle\left(1, 0\right),\left(0, 1\right)\right\rangle
The simplest way we can embed \mathbb{Z}^2 into \mathbb{R}^2 is by just mapping things trivially and looking at all points with integer coordinates. Unsurprisingly, we get a grid.
The lattice \left\langle\left(1, 0\right),\left(\frac12,\frac{\sqrt{3}}{2} \right)\right\rangle
If we want to be a tad bit more creative, we could try this hexagonal pattern. We can immediately tell that these two lattices are materially different. For example, in the first lattice, every lattice point has four closest neighbors, while in the second lattice we have six closest neighbors. As every board game nerd will tell you, the difference matters. A lot.
There are far more ways to create 2-dimensional lattices. So many in fact that you can prove all sorts of things about elliptic curves just by looking at 2d lattices, but that is a different blog post.
So to recap:
A lattice is a copy of the \mathbb{Z}^n, embedded into the \mathbb{R}^n.
Lattices have bases. They behave nicely, and don’t do weird ring shit.
The way the lattice is embedded matters.
Hard problems in lattices
While lattices are fascinating by themselves, we want to do cryptography, so we need to have hard problems. The two hard problems we will look at are called the Shortest Vector Problem (SVP) and the Closest Vector Problem (CVP).
The Shortest Vector Problem is the question “What vector other than 0 is the shortest vector in this lattice”. The zero vector is in all lattices and has length 0, so if we didn’t exclude it it would not be a very interesting problem.
The Closest Vector Problem on the other hand answers the question “Given a vector x, not necessarily in the lattice, which point in the lattice is the closest point to this vector?”
Answering (pink) the CVP for the vector \left(\frac53, \frac34\right)(red)
Good Basis, Bad Basis
At first, it might seem strange that the CVP and the SVP are considered hard problems. After all, you probably didn’t need to even get out a calculator or measuring tape to solve that example CVP, and I didn’t even bother to prove that 4 neighbors, 6 neighbors stuff which is basically the SVP, so what is supposed to be so hard about this?
The problem is, we only looked at this problem in 2 dimensions. But for lattice cryptography, we use something more like 768 dimensions. Unfortunately, graphics cards have trouble rendering those, so we will have to build some intuitions with numbers.
In the example we found that the closest vector to \left(\frac53, \frac34\right) is the lattice point (2, 1). How did my computer calculate this closest vector? Well I told it to round \frac53 to 2 and \frac34 to 1. Exciting stuff.
Let’s look at a completely, totally different lattice, the one generated by \{(2, 3), (5, 7)\}. If we now want to know what is the closest lattice point to (\frac53, \frac34), we first need to change basis to our lattice basis, round, and change back to the standard basis. We see that (\frac53, \frac34) = -\frac{95}{12}\cdot(2, 3) + \frac72\cdot(5, 7), rounding gives us -8\cdot(2,3)+4\cdot(5,7) = (4, 4). Let’s plot this:
The starting point (red) and the “closest” point (pink)
Wait, what? First of all, it turns out, this completely, totally different lattice is the same lattice as before, because (1,0)=-7\cdot(2,3) + 3\cdot(5,7) and (0, 1) = 5\cdot(2,3) -2\cdot(5,7). Turns out, I “accidentally” just used a different basis of the very same lattice. But why did our rounding trick not work? Let’s work backwards: Our solution should be (2,1) = -9\cdot(2,3)+4\cdot(5,7). So we almost got there, but rounding was still off by one in the first coordinate. In 2 dimensions, that’s not a big deal, just brute force by adding or subtracting 1 from each coordinate and see if you find a closer point. Of course, if the dimension is something like 768, brute forcing isn’t going to help.
This means that there are good bases and bad bases. In a good basis, we can just round the coefficients to solve the closest vector problem. In a bad basis however, if the dimension is high enough, you are hopelessly lost. And it turns out the bad bases outnumber the good ones, and if you have a good basis and want a bad one you just randomly base change a bit. (The example basis was literally my first try).
Now there is a way to go from a bad basis to a good basis, with a method called lattice reduction. But this blog post is already too long, so I won’t go into that. Suffice to say it’s hard to get a good enough basis in high dimensions.
A problem that is hard, but only if you don’t know some secret? This is very promising, let’s do some cryptography!
And how do I encrypt with this?
With all that lattice knowledge, we can dive right into learning with errors.
As parameters, we need a prime q, and lattice rank n. Popular choices are primes like 3329 and ranks like 768. One somewhat sour note is that we will unfortunately only encrypt a single bit.
To generate a key, we need a matrix A, where we take the coefficients uniformly at random between 0 and q. This matrix could theoretically be a public parameter, but choosing it per key makes it impossible to attack all keys at once.
The next thing we need are two vectors, s and e, with small coefficients. And by small we usually mean something like -1, 0, or 1. Maybe the occasional 2, but not larger. We then compute t = A^Ts + e \mod q and make (A, t) the public key, keeping s for the secret key.
To encrypt, we will need two more vectors r and f, also with small coefficients and a small integer g. We kind of do the same thing as with key generation and compute u = Ar + f \mod q as well as v = t^Tr + m\cdot\frac{q-1}{2}+g \mod q. To build some intuition let’s look at what size those terms have. Since we multiplied with a bunch of uniformly distributed stuff, t and u are also uniformly distributed. g as discussed is small. m\cdot\frac{q-1}{2} is either 0, a number generally considered fairly small, or \frac{q-1}{2}, a number which, modulo q is the largest possible (we allow negative numbers, so if we make it any bigger it just wraps around). Since t was uniformly distributed, t^Tr is as well. Which is good, since that means it masks whether our message term is big or small, and with only a single message bit, we should better try protecting it.
So how do we decrypt? Easy, just compute m' = v - s^Tu \mod q and output 0 if it’s small and 1 if it’s large. Since
The first two terms cancel. The last three terms are small, more precisely not larger than 2n. So m' is large if and only if m was 1, at least as long as we choose our parameters so that the rank is not too large compared to the prime.
Cherchez la lattice
So you might say, that’s nice and all, but where is the freaking lattice? All that stuff about closest vectors and bad bases and so on, it doesn’t look like we actually used any of it. And you’d be right. Lattices are kind of weird in that they are everywhere in arithmetic number theory, but they like to hide a bit sometimes. So let’s find this lattice, by attempting to break this scheme.
We want to recover the secret key s from the public key A, t = A^Ts+e \mod q. Let’s do this in two steps. First, we try to find any vectors s' and e' that solve t=A^Ts'+e'\mod q, without caring whether or not they are short, and then we can try to modify them to be short.
We can rewrite our equation as (A^T, \operatorname{Id}, q\operatorname{Id})(s', e', k) = t with k being some integer vector that we just use so we don’t have to worry about the \mod q part. This is solving a linear equation over the integers. It’s not quite as straightforward as the standard Gaussian algorithm, but a small modification by Smith will solve it and give us both a special solution (s', e', k) and a basis of the kernel of (A^T, \operatorname{Id}, q\operatorname{Id}). Recall that any solution, including the short s and e we are looking for differ from s' and e' by an element of the kernel.
Hmm, looking more closely at that kernel, it is a \mathbb{Z}-module by virtue of being a kernel, it has a basis, so it is free, and the basis is finite, so it is finitely generated. We don’t really care about the last n coefficients though which we only needed for the modulo, but we can just drop them, and the result remains a free, finitely generated \mathbb{Z}-module. Given that we want to find short vectors, and our notion of shortness was just the normal Euclidean norm, we can embed this kernel into \mathbb{R}^{m} trivially, and have found a lattice. In fact, we have found the lattice, since with a good basis we could find the vector (s_0, e_0) closest to (s', e') in the kernel lattice, which means their difference would be short, and indeed it would be (s, e) (even if it was not, what the only property for the decryption algorithm to work is the s and e are short, so it would just decrypt).
Smith unfortunately gives us a very large special solution and kernel basis vectors that very much are a bad basis of the kernel, which means that we won’t be able to find this closest vector, and this property gives Learning With Errors its security.
Closing Remarks
Since we have encrypted a single bit, if we used the scheme as is, it would be incredibly wordy, since we would need to repeat all of this 128 times (or more) to actually transmit a key. Kyber (or ML-KEM in NIST terms) uses some trickery to both make keys and ciphertexts smaller and operations faster, but I won’t go into them in this blog post.
Also, just like textbook RSA, the algorithm I presented here would not be secure in interactive settings, and needs additional modifications to ensure that we cannot extract the secret key by sending several related messages and observing whether the decrypting party use the same or a different key. But this too would need a separate blog post.









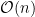

![\alpha = \sqrt{a}-\lfloor\sqrt{a}\rfloor\in[0, 1]](https://s0.wp.com/latex.php?latex=%5Calpha+%3D+%5Csqrt%7Ba%7D-%5Clfloor%5Csqrt%7Ba%7D%5Crfloor%5Cin%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)