Sigh. I really didn’t want to have to write this blog post. There is a story going around, claiming that the NSA somehow unduly influenced NIST to choose Kyber over NTRU, despite Kyber not being secure enough. The story is based on this blog post, by famous cryptographer Daniel J. Bernstein (also known as djb), who happens to be one of the authors of the NTRU variant NTRU-prime, which was also competing in the NIST competition. This has confused a bunch of people leading to some asking for a writeup and explanation of what happened. I tried to procrastinate until the problem went away, but people keep asking, so here we go.
Summary
Kyber512 is not less secure than required for NIST security level 1. In an attack model that significantly favors symmetric schemes over asymmetric schemes, there is a small discrepancy of less than 6 bits, or a factor 64 that Kyber512 appears weaker than AES-128. When changing the model to be more realistic, the problem goes away. NIST did not make basic mathematical errors in their analysis.
Defining Security Levels
There are two pieces to this discussion, and to understand what’s at going on, we need to first talk about security levels.
Level 1: The applied definition:
A scheme has a security level of n bits, if it is as hard to break as an ideal block cipher with an n bit key on a hypothetical computer that can evaluate the block cipher once every cycle. In other words, security level n means an adversary has to use at least 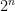
This is a very useful definition, and it’s usually what we think of when talking about security levels. You can use it to make some back of the envelope calculations, by sticking in some tact frequencies and core numbers or maybe some energy cost and solar outputs, to convince yourself that 128 bit ciphers are probably good enough in many scenarios. It is also obviously deeply flawed: Ideal block ciphers don’t exist, no computer can evaluate a full AES block encryption in a single cycle, and no adversary would use a Turing complete, general CPU to brute force, when special purpose hardware would be far more powerful, not wasting time and energy on the control flow of a problem that doesn’t really need such a thing. Enter the gate model:
Level 2: NIST’s definition (paraphrased)
A scheme has a security level of n bits if it is as hard to break as AES-n
NIST’s actual definition is a bit more complicated, in that it also mentions SHA-2 in various levels, but since the discussion is only about NIST’s level 1, i.e. at least as hard as AES-128, we don’t really need to get into that.
At first, this definition doesn’t seem to be all that different from the first one, only replacing the ideal block cipher with AES. But this change makes a huge difference, since now we do not need a hypothetical computer, but can actually concretely compute the gate cost of the brute forcing attack. Which is what people did. The main paper people are arguing about is this one by Matzov. It comes with a convenient table:

Table with gate counts by Matzov
As you can see, when counting gates, AES-128 requires 

Data locality
Now is the time to introduce the second concept I hinted at above: Data locality. If you have any experience with distributed computing, or even just micro optimizations, you have likely run into this: Even though on paper algorithm A should be faster than algorithm B, in practice algorithm B wins almost all of the time. A linear scan outperforms a tree map, which in turn outperforms a hash map, for example. There are usually two reasons for such a behavior: constant overhead, and data locality. I will focus here on the latter, although the former has also been cited as a counterargument to the claimed attack. The reason a linear scan can outperform a tree or a hash on small to medium size lookups is due to the CPU being able to stream in data from the RAM for the scan, making it so the data is available to be compared constantly, and we don’t have to waste cycles waiting for data to arrive from the RAM. One good way of visualizing this wait time is to calculate that at 3 GHz, data traveling at the speed of light will only make it 10 cm (~62 micromiles) per cycle. It doesn’t matter how fast your RAM is, if you cannot stream your data, you will be wasting several cycles for data to arrive, which in the case of a tree map or a hash collision can add up quickly. Of course this effect will not save the linear scan forever, and if you add enough elements, the asymptotic complexity will take over, but note that this is not merely a constant term effect either, as the required space of a circuit grows when scaling up. How we access data matters, and there are tons of tradeoffs to be had, for example whether to force your circuit to synchronize to allow for things like streaming data, but also forces you onto the same cycle based machine we wanted to avoid for extra efficiency above, etc. Since the length of wires and the cost having a synchronization signal travel through our circuit is not accounted for in the gate model, it makes sense that we might need to adjust values a bit for that, even more so when we start distributing algorithms over multiple machines, where these effects start to dominate in almost all practically relevant computations, as in it is usually more important where your data is than how many compute nodes you have to process it.
Now let’s quickly look at the data dependencies of our brute force algorithm. Quickly because there simply aren’t any. Brute force computations are lazily parallel, you simply divide the search space up arithmetically, and have completely independent brute forcing units happily brute forcing over their assigned chunk of work, until one of them is successful. In other words, the gate model will overestimate the cost of a brute force attack compared to any attack that requires data dependencies.
And, as it turns out, lattice reduction attacks have data dependencies. So much so that parallelizing lattice reduction on a single machine is non-trivial, and parallelizing it over multiple machines is an area of active research. Lots of numbers have been thrown around to adjust gate counts for these estimates, but it seems fairly reasonable that a factor of 50 is well within the margin of error here. In the end the difference in Matzov’s paper is small enough, that NIST’s confidence in Kyber512 still meeting NIST’s definition being well placed, and accepted by all but one of the cryptographers I know of. In particular, NIST’s analysis is very much careful, grounded in research, and does not contain basic math errors.
Closing thoughts
Lastly, my personal opinion on the technical question at stake here (I don’t care much for the personal attacks and polemic that has been thrown around). In my opinion, when you can afford it, you should be using Kyber768 instead of Kyber512. This is not due to any currently existing attacks, and I do not think NIST should change their planned standardizations and recommendations, but purely a precautionary step, and in situations where Kyber512’s performance and overhead is required, it is a solid choice. My reasoning to prefer Kyber768 comes from the fact that there are two types of attacks it might be facing:
- Improvements of lattice reduction attacks
- Algebraic attacks using the additional structure of MLWE over LWE
The former family of attacks is likely to occur, and likely to chip small amounts of the security level of Kyber, without fundamentally threatening the soundness of the algorithm itself. This is what we have seen happening to e.g. RSA in the case of the general number field sieve, where small improvements over time pushed RSA-1024 within reach of modern hardware to factor. Lattice reduction similarly has a tuning space and while the approach is unlikely to break Kyber, it might reduce the security level of Kyber512 below what I’m comfortable with. The second type of attack is far scarier, as increasing the security level slightly is not guaranteed to help much here, and I hope that such an attack does not exist. While it is possible to construct a Kyber640 variant relatively easily, in my experience, Kyber768 is pretty much always acceptable in practice, much simpler, and has a far more comfortable security margin. The same consideration holds for NTRU, which faces the exact same attacks, and I would aim for NIST level 3 there as well. Kyber scales quadratically in time, which is favorable to the cubic scaling behavior of elliptic curves, and makes bumping up the security level less painful.
Lastly, a few thoughts on comparing MLWE (Kyber) vs. NTRU more broadly.
From my perspective as a mathematician, MLWE is the more beautiful problem. This is a fairly useless observation, as mathematical beauty is fairly subjective, and it is not clear whether the more beautiful problem is more secure, but I cannot deny that I find the rather clunky feeling nature of NTRU somewhat offputting.
From my probably more relevant perspective as an applied cryptographer, MLWE is easier to implement and promises greater performance compared to NTRU at a very comparable security level. While these might seem like “nice to haves”, these considerations tend to matter greatly in practice, and are often what makes or breaks a cryptographic algorithm. The easier the algorithm is to implement correctly, the less I have to worry about side channel attacks bypassing the entire cryptosystem. In the end, attackers rarely try to brute force keys, but quite frequently exploit much more common problems in implementations. Performance and overhead are similarly important to the security of the overall system: If algorithms are too slow, they often end up being underused and put into more fragile, but less expensive protocol constructions. Any analysis that is based on a holistic threat model of the entire system will have to take these considerations into account, and from that perspective alone Kyber, including Kyber512, are the better algorithm choice. NIST has learned this lesson the hard way, with SHA3, despite being the better construction, struggling to gain on SHA2, due to having a far too conservative security margin and a CPU architecture unfriendly implementation.