FN-DSA (née Falcon) is a proposed post-quantum signature standard that keeps polarizing engineers. Cryptography engineers on the one hand, tasked with potentially implementing this monstrosity, hate it with a passion. Protocol engineers on the other hand, especially when working with UDP, see a glimmer of hope that they might not have to deal with packet fragmentation and really would like to use it.
For the most part, I agree with my fellow cryptography engineers that the best approach to using FN-DSA is to not. However, prohibition is a failed approach, whether we are talking about drugs or about cryptography, so, in the interest of harm reduction, here are the essential caveats for anyone who wants to use FN-DSA, so that they can do so as safely as possible.
State of standard
The biggest problem with FN-DSA is that the standard currently does not exist. NIST has prepared an initial public draft (ipd) in August 2025, but this draft, at least as of writing this article in May 2026, is stuck somewhere in NIST’s publishing pipeline with unclear status so it continues to be more of an initial private draft for the time being.
Not having the ipd out means that all the points I’m making here are based on the round 3 candidate named Falcon that will eventually turn into FN-DSA, and it is very much possible that some or all of these points will be addressed in the actual ipd. Or the actual standard for that matter. Importantly, going from ipd to standard will take around a year, if the same scrutiny is applied as was with ML-KEM/ML-DSA/SLH-DSA, and an argument can be made that if anything FN-DSA might require substantially more scrutiny due to the complexity of the algorithm. There are usually breaking changes introduced between ipd and actual standard, so this means that anyone hoping that they can just start using FN-DSA to solve all their size related problems will have to wait for at least one, and possibly multiple years for the standard to actually be ready to implement.
Prehashing FN-DSA
Prehashing is a very strange topic. Half of the cryptographic community insists that it’s absolutely essential, while the other half has never heard of it. Usually the half that has never heard of it is theoretical cryptographers, which are very much not the target audience of this blog post, so I’ll keep the explanation of what prehashing is short. A much more thorough discussion can be found in my blog post on prehashing ML-DSA.
In a nutshell, prehashing turns signature generation into a multi-party algorithm, with one party (the signer) holding the private key, but having only limited computing resources, while the other party (the hasher) holds the message and has no limit on its computing power. In this scenario, one wants to limit the amount of data that is transferred to the signer, ideally to just a hash. In order to make this process transparent to any verifying parties, people usually want the resulting signature to be a fully standard compliant signature of the message, with no extra hash that the standard didn’t mention applied to the message.
Classical signature algorithms, in particular for RSA and ECDSA signatures usually decompose into a hashing step and a signing step. Practitioners, seeing this decomposition, took this as a natural way to introduce prehashing, with the hasher computing the hash and the signer than operating on this hash to compute the rest of the signature. This goes so far as X509 certificates defining the hash function to be used for a given message with that message, instead of with the corresponding public key, making X509 certificates technically not a fully defined signature scheme.
For RSA and ECDSA, this is mostly, but not entirely benign. RSA in particular has a forgery attack, where the hasher can forge a signature for a message the signer has never seen the hash of. However, as the signer only ever sees hashes of messages to begin with, it cannot actually do any meaningful verification of the message itself, and forgery attacks by the hasher are not considered relevant in the prehashing threat model. Key recovery attacks, on the hand, very much are. The point of prehashing is, after all, to have the private key in some environment that makes exfiltration substantially harder than if it was on the hasher, so any attack that allows the hasher to recover the key would be catastrophic and defeat the point of employing prehashing to begin with.
And it turns out Falcon has just one such key recovery attack. To understand why, one needs to realize that hash functions are used for two different purposes in signature schemes: As message compression and as a model for a random function. Prehashing works fine as long as the hash function is only used for compression, and starts to break when it also has to serve other security guarantees.
For Fiat-Shamir transformed signature schemes, the security relevant hash function will always be buried somewhere deeper in the signing algorithm, as the hash needs to include both the message and the commitment, which is only computed later in the algorithm. ML-DSA has a separate message compression hash (which computes the infamous µ), which can be used for prehashing. ECDSA is a YOLO signature scheme that doesn’t really have a clear security reduction, and just doesn’t hash the commitment into its challenge, and as far as we know nothing horrible happened.
RSA however, just like FN-DSA, is what is called a hash-and-sign scheme. Hash and sign schemes generally work by having some trapdoor function 




And now for the kicker: FN-DSA not only allows for forgeries when you take away its hash function, it flat out starts leaking its private key. The only way to have a secure FN-DSA implementation is for the signer to pick a random value, concatenate it with the message, hash and then compute the signature for that essentially random value. Signing non-random values will break the scheme.
At least in the round three algorithm description, there is no way of safely prehashing FN-DSA, but there is a very tempting looking hash function call that invites careless implementers to do so anyway. The only viable option to prehash FN-DSA is to introduce a separate message compression hash, and double hash the message.
About those floating points
Probably the most frequently talked about property of FN-DSA is that the spec uses floating point numbers. The floating point numbers are intrinsic to the mathematics of the algorithm (see the section below, where there will be copious mentions of 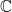
It is, however, possible to implement floating point operations in constant time. To do so, we just have to crack open our numerical analysis textbooks and implement floats by hand, by tracking two integers per floating point, one for mantissa and one for exponent. Multiplication is very straightforward to constant-timefy, in fact it’s likely already constant time and requires just two integer operations. Addition is slightly trickier, but also not the end of the world. You will need some constant time compares to properly shift both numbers to align, but not a big deal and only a relatively minor performance penalty. Division, however, is a nightmare. The standard division algorithm used for floating points is an iterative process using multiple multiplications and additions every iteration and returning when the result is accurate enough.
For a constant time algorithm, that will not do, and we can only return after having iterated for the same number of steps in any case, turning everything into worst case performance. We can calculate this iteration limit without much difficulty, but no currently existing hardware and only very limited existing software implementing things this way exist. On top of that, this forces us to have worst case complexity for every case, and, especially in the case of software implementations, it makes things terrifyingly slow.
When I implemented Falcon in my bad computer algebra system, a good portion of the time was spend refactoring my existing arbitrary precision floating point logic to switch to doubles when the arbitrary precision was arbitrarily set to 64 bits, solely because my non-constant time software implementation of floating point division logic was so painfully slow that I got to tired waiting on it while debugging the algorithm.
This has important performance implications for your signers. While FN-DSA’s verification logic is especially fast and simple, signing will either be horrendously slow or not constant time, in each case it might disqualify your application from having live signing.
Speaking of debugging the algorithm, another fun quirk of floating point logic is that it is only defined up to epsilon. Different implementations of the same IEEE floating point standard will give different results on some inputs. Usually that does not matter much, since the differences are only in the least significant bits, they are rounding errors, after all, so people working with floating points usually do not care about it, they either have done a proper error calculation, if they are numerical analysts, or they just accept things being subtly wrong. For cryptographers, on the other hand, this means that test vectors don’t quite work. In fact, Falcon was the first and only time I ever had to use a statistical test to debug an especially gnarly error in the implementation.
Variable signature sizes
Another fun quirk of FN-DSA is that the signature may or may not be variable in size. This is not as unusual as it first seems, in fact, if you had a look at your average ML-DSA signature, you’ve likely noticed the suspicious amount of zero bytes a valid signature has at the end. This is because ML-DSA signatures are also variable in size, the standard just pads them out to all be the same size.
For FN-DSA we don’t know yet what NIST will write in the standard, but they at least considered not doing that. After all, the whole point of FN-DSA is to be small, and padding signatures is the opposite of that. So be aware that signature may or may not be variable in size.
There is classical precedent for variable size signatures: ECDSA signatures, when encoded in ASN.1 format, are not constant in size. If ECDSA is used in the superior IEEE format, this is not the case however. And as you might guess by me calling it superior, the variable size signatures tend to cause some problems, to the point that if a team complains to me about a flaky verification failure, I pretty much already can tell you before looking at the artifacts that it happens because zeroes are not added or removed properly from the signature, leading to a 1/256 chance of ASN.1 signatures being malformed. All in all, this is a workable property, but definitely not one that has never caused a bug.
The math of FN-DSA
Lastly, a bit on the mathematics of FN-DSA. I will keep this section short and not go very deep here, given that the target audience is application developers and not cryptographers, maybe I will do so in a follow-up. But in short: The mathematics of FN-DSA are stunningly beautiful. It is based on NTRU instead of LWE, that means that instead of computing 


With this short lattice basis, we can now solve the closest lattice problem. And in order to sign, we do just that: We sign an integer 


However, if we actually really solved the closest vector problem when signing, we would leak information about our short basis, so what we do instead is use our basis to find a “close enough, but not necessarily the closest” vector. This is where all the tricky computation comes in, and where Falcon is deeply intertwined with the number field logic that ML-DSA just uses as a convenient speed-up. In order to compute this point, we look at the complex embeddings of the number field, use the fact that those are reflected in Fast Fourier Transforms, and that those FFTs translate to NTTs when the number field order is quotiented out by 
In order to be secure, as mentioned in the first paragraph, we need to ensure that we never sign the same message twice, and that we never let the attacker chose the integer we sign. We do this by, instead of hashing our message directly, hashing our message together with a random integer, i.e. that means we sign (and verify) a message by computing (or checking) 

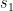
That is the very abridged version of how the mathematics works, there is a lot more to say about how those Fourier transforms work and help with computing close but not too close lattice points, but if I ever end up explaining that part of the math, in needs to be in a separate blog post, so I can still tag this one as comprehensible cryptography.
One reply on “So you want to deploy FN-DSA”
Hi Sophie,
Thanks for this honest take on Falcon. I do agree with some of your points, but not all. Disclosure I am a co-author of Falcon, apologies in advance for any bias in my answer.
Pre-hashing. I am indeed part of “the other half [that] has never heard of it”. From what I understand, the hypothetical pre-hashing mode you describe is to define the “pre-hash” c as c = H(msg, salt). I agree with you that this should not be done, but there are plenty of other viable solutions, one of which is even hinted at in your post. For example c = H1(H(msg), salt) seems like it would achieve the functional goal of allowing delegating the computation of H(msg) to another device? As long as salt is sampled randomly during signing, this is fine. If you want to hash pk as well, then c = H1(H2(pk), H(msg), salt) works and you can precompute and store H2(pk).
Floating points. I heartily agree with you that these are super annoying, both from an implementation and a security analysis perspective. This is a bit of an early teaser, but I’ve been working with fellow researchers for about a year on a fixed-point implementation of Falcon, and the TL;DR is that Falcon can be implemented with 64-bit fixed-point integers instead of float64, with minimal impact on security and requiring only minimal changes to the spec. We got a paper at CRYPTO showing this, and we will publish it shortly after the camera-ready deadline of CRYPTO (8 June). Now I know this is technically “spec-breaking”, but we have communicated our paper to NIST, will communicate it to the pqc-forum as well, and hope that both will see enough value in this proposal so that it gets pushed into the standard.
Variable signature sizes. The latest version of the spec, from October 2020, enforces that signatures have a fixed length. Now I know that the reference implementation is more ambiguous and also supports variable lengths, but the spec is clear on this. I do not know what the IPD will say, but I hope they will enforce fixed length.
The math of FN-DSA. I agree with you — it’s too complicated. There are techniques in the literature to simplify the signing procedure of Falcon (notably “Antrag”), and I pushed in 2024 (https://csrc.nist.gov/Presentations/2024/falcon) to use the “Antrag”, but so far it seems NIST has decided to keep Falcon as-is.