What is this?
There have been some recent concerns about ML-KEM, NIST’s standard for encryption with Post-Quantum Cryptography, related standards of the IETF, and lots of conspiracy theories about malicious actors subverting the standardization process. As someone who has been involved with this standardization process at pretty much every level, here a quick debunking of the various nonsense I have heard. So let’s get started, FAQ style.
Did the NSA invent ML-KEM?
No. It was first specified by a team of various European cryptographers, whom you can look up on their website.
Okay, but that was Kyber, not ML-KEM, did the NSA change Kyber?
No. The differences between Kyber and ML-KEM are pretty minute, mostly editorial changes by NIST. The only change that could be seen as actually interesting was a slight change to how certain key derivation mechanics worked. This change was suggested by Peter Schwabe, one of the original authors of Kyber, and is fairly straightforward to analyze. The reason for this change was that originally, Kyber was able to produce shared secrets of any length, by including a KDF step. But applications usually need their own KDF to apply to shared secrets, in order to bind the shared secret to transcripts and similar, so you would end up with two KDF calls. Since Kyber only uses the KDF to stretch the output, removing it slightly improves the performance of the algorithm without having any security consequences. Basically, there was a feature that turned out to not actually be a feature in real world scenarios, so NIST removed it, after careful consideration, and after being encouraged to do so by the literal author of the scheme, and under the watchful eyes of the entire cryptographic community. Nothing untoward happened here.
Edited to add (2026-07-09): One of the minor things that NIST changed was recently dragged out again by a disgraced former cryptographer, the so called hash of shame. In the draft for Kyber, the encapsulating party would, after drafting randomness from a random number generator, hash this randomness before proceeding with the encapsulation algorithm. NIST, removed this extra hash after Markku and I asked for it. The original inclusion for this hash was to defend against DUAL_EC_DRBG, which requires unprocessed output of the DRBG to abuse its backdoor. However, the far easier way of defending against this problem is simply not using DUAL_EC_DRBG. Random number generators (both TRNGs and DRBGs) are crucial for the safe operation of any cryptographic algorithm. There are multiple failure modes of both TRNGs and DRBGs, only one of which is a DUAL_EC_DRBG type backdoor. DUAL_EC_DRBG was never a particularly popular DRBG, and as such it was deprecated by NIST without much of a problem. I’ve never seen it implemented, much less deployed anywhere in my career. I’ve seen plenty of bad random number generators, but none of those would have been fixed by unilaterally adding a hash, so this hash, while useful as a sign of protest against the intentional weakening of standards by nation state actors, should not be in the final standard, as it just slows down the resulting algorithm without anything gained. Weak random number generators are absolutely a concern, but the way to fix this problem is by fixing the random number generator, not by inventing a new ad hoc DRBG in a layer above.
Okay but what about maybe there still being a backdoor?
There is no backdoor in ML-KEM, and I can prove it. For something to be a backdoor, specifically a “Nobody but us backdoor” (NOBUS), you need some way to ensure that nobody else can exploit it, otherwise it is not a backdoor, but a broken algorithm, and any internal cryptanalysis you might have will be caught up eventually by academia. So for something to be a useful backdoor, you need to possess some secret that cannot be brute forced that acts as a private key to unlock any ciphertext generated by the algorithm. This is the backdoor in DUAL_EC_DRBG, and, since the US plans to use ML-KEM themselves (as opposed to the export cipher shenanigans back in the day), would be the only backdoor they could reasonably insert into a standard.
However, if you have a private key, that cannot be brute forced, you need to have a public key as well, and that public key needs to be large enough to prevent brute-forcing, and be embedded into the algorithm, as a parameter. And in order to not be brute forceable, this public key needs to have at least 128 bits of entropy. This gives us a nice test to see whether a scheme is capable of having cryptographic NOBUS backdoors: We tally up the entropy of the parameter space. If the result is definitely less than 128 bits, the scheme can at most be broken, but cannot be backdoored.
So let’s do that for ML-KEM:

This is the set of parameters, let’s tally them up, with complete disregard for any of the choices being much more constrained than random integers would suggest (actually, I am too much of a nerd to not point out the constraints, but I will use the larger number for the tally).
- Degree of the number field: 8 bits (actually, it has to be a power of two, so really only 3 bits)
- Prime: 12 bits (actually, it has to be a prime, so 10.2 bits (Actually, actually, it has to be a prime of the form
, and it has to be at least double the rank times degree, and 3329 is literally the smallest prime that fits that bill))
- Rank of the module: 3 bits (well, the rank of the module is the main security parameter, it literally just counts from 2 to 4)
- Secret and error term bounds: 2 + 2 bits (really these come from the size of the prime, the module rank, and the number field degree)
- Compression strength: 4 + 3 bits
In total, this gives us 34 bits. Counted exceedingly generously. I even gave an extra bit for all the small numbers! Any asymmetric cryptosystem with a 34 bit public key would be brute forceable by a laptop within a few minutes, and ML-KEM would not be backdoored, but rather be broken. There is no backdoor in ML-KEM, because there simply is no space to hide a backdoor in ML-KEM.
And just to be sure, if you apply this same counting bits of parameters test to the famously backdoored DUAL_EC_DRBG, you indeed have multiple elliptic curve points defined in the standard without any motivation, immediately blowing our 128 bits of entropy budget for parameters. In fact, it would be trivial to fix DUAL_EC_DRBG by applying what’s called a “Nothing up my sleeves” paradigm: Instead of just having the elliptic curves points sit there, with no explanation, make it so that they are derived from digits of π, e, or the output of some hash function on some published seed. That would still not pass our test, but that is because I designed this test to be way too aggressive, as the remarks in the brackets show, there is not really any real choice to these parameters, they are just the smallest set of parameters that result in a secure scheme (making them larger would only make the scheme slower and/or have more overhead).
So no, there is no backdoor in ML-KEM.
But didn’t NIST fail basic math when picking ML-KEM?
No. In fact, I wrote an entire blog post about that topic, but “no” is an accurate summary of that post.
I thought ML-KEM was broken, something about a fault attack?
There are indeed fault attacks on ML-KEM. This is not super surprising, if you know what a fault attack (also called glitch attack) is. For a fault attack, you need to insert a mistake – a fault – in the computation of the algorithm. You can do this via messing with the physical hardware, things like ROWHAMMER that literally change the memory while the computation is happening. It’s important to analyze these types of failures, but literally any practical cryptographic algorithm in existence is vulnerable to fault attacks.
It’s literally computers failing at their one job and not computing very well. CPU and memory attacks are probably one of the most powerful families of attacks we have, and they have proven to be very stubborn to mitigate. But algorithms failing in the face of them is not particularly surprising, after all, if you can flip a single arbitrary bit, you might as well just set “verified_success” to true and call it a day. Technically, this is the strongest form of fault, where the attacker choses where it occurs, but even random faults usually demolish pretty much any cryptographic algorithm, and us knowing about these attacks is merely evidence of an algorithm being seen as important enough to do the math of how exactly they fail when you literally pull the ground out beneath them.
But what about decryption failure attacks? Those sound scary!
ML-KEM has a weird quirk: It is, theoretically, possible to create a ciphertext, in an honest fashion, that the private key holder will reject. If one were to successfully do so, one would learn information about the private key. But here comes the kicker: The only way to create this poisoned ciphertext is by honestly running the encapsulation algorithm, and hoping to get lucky. There is a slight way to bias the ciphertexts, but to do so, one still has to compute them, and the advantage would be abysmal, since ML-KEM forces the hand of the encapsulating party on almost all choices. The probability of this decapsulation failure can be computed with relatively straight-forward mathematics, the Cauchy-Schwartz inequality. And well, the parameters of ML-KEM are chosen in such a way that the actual probability is vanishingly small, less than 
On top of this, the average ML-KEM key is used exactly once, as such is the fate of keys used in key exchange, further making any adaptive attack like this meaningless, but ML-KEM keys are safe to use even with multiple decapsulations.
But wasn’t there something called Kyberslash?
Yeah. It turns out, implementing cryptographic code is still hard. My modest bragging right is that my implementation, which would eventually morph into BoringSSL’s ML-KEM implementation, never had this problem, so I guess the answer here is to git gud, or something. But really, especially initially, there are some rough edges in new implementations as we learn the right techniques to avoid them. Importantly, this is a flaw of the implementation, not of the mathematics of the algorithm. In fact, the good news here is that implementationwise, ML-KEM is actually a lot simpler than elliptic curves are, so these kinds of minor side channel issues are likely to be rarer here, we just haven’t implemented it as much as elliptic curves.
Okay, enough about ML-KEM, what about hybrids and the IETF?
Okay, this one is a funny one. Well funny if you likely deeply dysfunctional bikeshedding, willful misunderstanding, and drama. First of, what are hybrids? Assume you have two cryptographic schemes that do the same thing, and you distrust both of them. But you do trust the combination of the two. That is, in essence, what hybrids allow you to do: Combine two schemes of the same type into one, so that the combined scheme is at least as secure as either of them. The usual line is that this is perfect for PQC, as it allows you to combine the well studied security of classical schemes with the quantum resistance of PQC schemes. Additionally, the overhead of elliptic curve cryptography, when compared with lattice cryptography, is tiny, so why not throw it in there. And generally I agree with that stance, although I would say that my trust in lattice cryptography is pretty much equal to my trust in elliptic curves, and quite a bit higher than my trust in RSA, so I would not see hybrids as absolutely, always and at every turn, superduper essential. But they are basically free, so why not? In the end, yes, hybrids are the best way to go, and indeed, this is what the IETF enabled people to do. There are various RFCs to that extent, to understand the current controversy, we need to focus on two TLS related ones: X25519MLKEM768 aka 0x11EC, and MLKEM1024. The former is a hybrid, the latter is not. And, much in line with my reasoning, 0x11EC is the default key exchange algorithm used by Chrome, Firefox, and pretty much all other TLS clients that currently support PQC. So what’s the point of MLKEM1024? Well it turns out there is one customer who really really hates hybrids, and only wants to use ML-KEM1024 for all their systems. And that customer happens to be the NSA. And honestly, I do not see a problem with that. If the NSA wants to make their own systems inefficient, then that is their choice. Why inefficient? It turns out that, due to the quirks of how TLS works, the client needs to predict what the server will likely accept. They could predict more things, but since PQC keys are quite chonky, sending more than one PQC key is making your handshakes slower. And so does mispredicting, since it results in the server saying “try again, with the right public key, this time”. So, if everyone but the NSA uses X25519MLKEM768, the main effect is that the NSA has slower handshakes. As said, I don’t think it’s reasonable to say their handshakes are substantially less secure, but sure, if you really think ML-KEM is broken, then yes, the NSA has successfully undermined the IETF in order to make their own systems less secure, while not impacting anyone else. Congratulations to them, I guess.
But doesn’t the IETF actively discourage hybrids?
No. To understand this, we need to look at two flags that come with TLS keyexchange algorithms: Recommended and Mandatory To Implement. Recommended is a flag with three values, Yes, No, and Discouraged. The Discouraged state is used for algorithms known to be broken, such as RC4. Clearly ML-KEM, with or without a hybrid, is not known to be broken, so Discouraged is the wrong category. It is true that 0x11EC is not marked as Recommended, mostly because it started out as an experimental combination that then somehow ended up as the thing everybody was doing, and while lots of digital ink was spilled on whether or not it should be recommended, nobody updated the flag before publishing the RFC. (technically the RFC is not published yet, but the rest is pretty much formality, and the flag is unlikely to change) So yes, technically the IETF did not recommend a hybrid algorithm. But your browsers and everybody else is using it, so there is that. And just in case you were worried about that, the NSA option of MLKEM1024 is also not marked as recommended.
Edited to add (2026-06-30): In the meantime, the IETF has ended up updating the IANA registry flipping the bit for 0x11EC to recommended. Pure MLKEM1024 continues to not be recommended.
Lastly, Mandatory To Implement is an elaborate prank by the inventors of TLS to create more discussions on mailing lists. As David Benjamin once put it, the only algorithm that is actually mandatory to implement is the null algorithm, as that is the name of the initial state of a TLS connection, before an algorithm has been negotiated. Otherwise, at least my recommendation, is to respond with this gif

whenever someone requests a MTI algorithm you don’t want to support. The flag has literally zero meaning. Oh and yeah, neither of the two algorithms is MTI.
Edited to Add: Bonus Rounds
I got a few additional questions after this blog post was published, so I’m adding them here.
But won’t IETF/browser/server support open us up to downgrade attacks?
No. TLS key negotiation is robust against downgrade attacks. If your browser is some 10 years out of date, it might be vulnerable to downgrade attacks to SSL3, but in that case, I would also not worry about PQC.
In more technical detail, both the client’s list of supported ciphers and the server’s pick of cipher are added to the key derivation, so any manipulation of these choices will not result in a successfully negotiated TLS 1.3 key. TLS 1.3’s downgrade protections are even more fun, a server that could support TLS 1.3, but is negotiating TLS 1.2 needs to set a specific server random, to signal to the client that it would really have preferred TLS 1.3. Combined, this protects TLS 1.3 key negotiations, and so adding additional key agreements that neither the clients nor the server prefers will never be picked.
But why does the NSA not like hybrids?
This is a point I initially left out because all I can tell you is what the NSA says are their reasons to not like hybrids, and evaluate whether or not they are sensible, but I cannot tell you whether these are the actual reasons.
When it comes to their stated reasons, we have basically three that come up again and again:
- Fear of combinatorial explosion leading to interoperability issues.
- Lack of need due to using double encryption already.
- A wish to signal to the rest of the world (including, apparently, some parts of the US government itself), that the NSA trusts lattice cryptography.
When it comes to the first point, their assessment is somewhat half right: We have seen a huge combinatorial explosion because people desperately wanted support for their favorite classical scheme and their favorite PQC scheme, leading to somewhat ridiculous numbers of hybrids defined by the LAMPS, CFRG and PGP working groups. However, TLS key negotiation has not fallen into this trap. There is only one hybrid algorithm, and everybody seems to like and use it. Note that CNSA2, the guidance by the NSA that favorites not using hybrids, well predates even the first experiments with Kyber that eventually morphed into 0x11EC.
For the second point, it is important to know that apparently, in case of very sensitive information, it already is common practice for intelligence operations to encrypt twice, with stacks implemented by completely separate vendors. This makes sense, it protects both against insider threats and against implementation mistakes, albeit at a substantial performance penalty (I don’t know if they just don’t have performance critical super sensitive stuff). With this capability already being present, you can create a hybrid cipher by having one layer classical and the other one PQC, and do not need a hybrid key exchange.
The last point is something that is more between the lines and has come up in some more informal conversations: The NSA needs to show that they, and the oodles of mathematicians working for it, actually trust the PQC algorithms. While for any other organization using hybrids might just seem like a prudent choice, if the NSA does so, we would rightfully question whether they actually trust PQC enough for it to be deployed at all. By mandating the use of pure lattice based cryptography, but only for their own systems, they show that they are willing to put their money where their mouth is. In the end, this means that if lattice cryptography/ML-KEM turns out to be broken it is their systems only that are at risk.
As I said, these to me are reasonable arguments, but they of course do not mean that they are the actual motivations of the organization. Also keep in mind, that, like any large organization, there is not necessarily a single NSA opinion, but rather just different individuals that have different motivations
But could you add a backdoor to MLWE, if you wanted to, and how would that look like?
Okay, nobody asked this, but I’m going to answer it anyways, since this is my blog post.
MLWE is the underlying mechanism behind ML-KEM, the more general mathematical description of the problem instead of the very concrete description of which bytes go where. And if you wanted to backdoor it, you actually could: I’m going to describe this for RLWE, the ring version of MLWE, the principle is the same, but for rings it’s easier to write up. The public key 



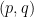



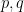

So if you wanted to backdoor an MLWE type algorithm, all you would need to do is to specify a single matrix 
But: This would fail the test I outlined above; The matrix
In case you wondered, the way ML-KEM choses it’s matrix is simple: Each public key gets their own, random matrix. Only the person running the keygen could potentially backdoor the matrix, and they have the private key anyways. And actually, they cannot even do that, since ML-KEM compresses the matrix by simply giving a derivation seed as the public key.
But are cryptographic NOBUS backdoors really the only option?
This was a question that I received several times. Fine, I proved that there cannot be a cryptographic NOBUS backdoor, but is that really the only option. In short, yes.
I think what threw people off here is that implementations can have much more sophisticated backdoors, since no test can guarantee the correct response to all queries, only to the queries tested. However, algorithms are different.
Any backdoor you want to insert into an algorithm needs to be inserted in the mathematical description of the algorithm itself, since anyone can chose to implement a given algorithm from scratch and expect it to interoperate. And this leaves you with only two options: A backdoor that theoretically anyone can find and exploit, aka a broken algorithm, or a backdoor that, even if found, can only be exploited by the person who put it there, aka a NOBUS backdoor. The former would make the algorithm unfit for your own use, as any such backdoor is likely to be discovered by interested parties sooner rather than later, given the intense scrutiny these algorithms are put under. The second type has to have some form of secret with enough entropy, otherwise an attacker can simply try all possible values that the backdooring party might possess to find the correct value, in other words, the backdoor would again be of the first type.
Edited to add (2026-07-01): A variant of this argument that I’ve seen is the question of whether there could be a break that only affects a certain percentage of keys (a so called weak keys issue). A state actor in possession of this break could then guard their own implementations against this break by adding some additional code to the key generation algorithm, while still being able to break a non-insignificant amount of traffic. However, this is also not a NOBUS backdoor: Everyone can find this problem by just reading the spec. That means it is only a matter of time until this issue is found, either by other adversaries or by the public. An adversary that only cares about their own traffic, and can highly control every single endpoint producing and consuming this traffic, might indeed not be overly motivated to share such a weakness. However, since the secure algorithm now no longer follows the spec (even if that deviance is not visible to the outside), this adversary can now no longer contract implementations out to a third party, as that third party would implement the original, flawed spec. In fact, as cryptography is usually indistinguishable from random (albeit, in the case of ML-KEM, not uniform random), they could run a completely different algorithm internally, and would not have to care about defensive uses of the standard at all. Even worse, if the adversary does not control all endpoints, or cares about traffic beyond their own, i.e. has any defensive interest in the standard at all, they would now again allow others to break this encryption. In the case where everyone but the adversary uses a hybrid scheme, not much of anything would happen as long as the classical cryptography remains secure. In general, the question of “what if there are some weak keys that only the NSA knows about” is more or less the same as “what if the NSA is pulling an elaborate bait and switch and just saying and contracting a bunch of ML-KEM work, but secretly using something else entirely”.