Yesterday, Chandler asked about an overview of the new PQC algorithms, including hybrids, for non-cryptographers. And since I’m currently procrastinating writing something about TLS, I might as well write that overview first.
Unfortunately, I am a cryptographer, which means I easily forget that the average person probably only knows what AEADs, Key Agreements, and of course Digital Signatures do.

XKCD no. 2501 “Average Familiarity”
So, I will do my best, but please tell me where a bit more detail is needed.
Overview
NIST has standardized three new algorithms, going by the names ML-KEM (aka FIPS 203 aka Kyber), ML-DSA (aka FIPS 204 aka Dilithium) and SLH-DSA (aka FIPS 205 aka SPHINCS+). The first is a Key Encapsulation Method, the other two are digital signature schemes. One thing they all have in common is their comparatively much larger sizes for public keys, ciphertexts, and signatures.
Additionally, I will also discuss X-Wing, a hybrid Key Encapsulation Method combining both classical and PQ algorithms, which is currently making its way through IETF.
Key Encapsulation
What is a KEM
We start of this overview of PQC algorithms with a new primitive, key encapsulation methods (KEMs). Technically, KEMs aren’t new, it just turns out that, while they are arguably the superior way of dealing with asymmetric encryption, they haven’t been used in very explicit ways.
So what is a key encapsulation method? Basically it is a primitive with the following interface, in some fake programming language vaguely resembling C++:
// Non-deterministic method
pair<PrivateKey, PublicKey> GenerateKeyPair();
// Non-deterministic method
pair<ByteString, Ciphertext> Encapsulate(PublicKey pk);
// deterministic method
ByteString Decapsulate(PrivateKey sk, Ciphertext ct);Here, you can see the close relation to asymmetric encryption, essentially a KEM is cryptographers saying that you shouldn’t actually decide what you want to encrypt, and instead that choice should be made for you. There is a good reasons for that: Asymmetric cryptography is far slower than symmetric cryptography, so really you should only ever encrypt a symmetric encryption key anyways, and a KEM just always does this for you. There is another advantage to always encrypting random numbers: It makes designing a cryptographic primitive far easier, because now the cryptographer doesn’t have to account for people encrypting “The eagle has landed” over and over again, and expecting that to be secure.
As an example, let’s look at RSA-KEM, a classical KEM that unfortunately never got the popularity it deserved:
pair<ByteString, Ciphertext> Encapsulate(PublicKey pk) {
// Select a random number between zero and the modulus.
BigInt msg = Random(0, pk.n);
// Hash the random number to obtain the shared secret.
ByteString shared_secret = Hash(msg);
// Compute msg^e mod n.
Ciphertext ct = ModPow(msg, pk.e, pk.n);
return make_pair(shared_secret, ct);
}Pseudocode for RSA-KEM. This is an actually secure and standardized way of using RSA.
Basically, this is RSA as you learned it in high school/college, without all that weird optimal padding stuff that OAEP has to add just to allow you to encrypt your “arbitrary message” which usually is just random numbers anyhow.
So now that we know how to build a KEM out of RSA, let’s quickly also do so with elliptic curve, so we can accurately compare to PQC algorithms. Actually, it’s not even so much elliptic curves, but any Diffie-Hellman like key agreement scheme. So again, with fake C++ inspired pseudo code:
pair<ByteString, Ciphertext> Encapsulate(PublicKey pk) {
PrivateKey eph_sk;
PublicKey eph_pk;
// Create an ephemeral key pair.
std::tie(eph_sk, eph_pk) = GenerateKeyPair();
ByteString shared_secret = KeyAgreement(eph_sk, pk);
return make_pair(shared_secret, eph_pk);
}Pseudocode for ECIES-KEM. This is not a secure KEM as is, but the details to make it secure are not interesting here.
Basically, to use ECDH as a KEM we create an ephemeral key pair, use the ephemeral public key as ciphertext and use the key agreement to create a shared secret. Again we can see how it simplifies the algorithm to not let the caller chose what is encrypted, here by using that we cannot actually control which secret is agreed upon, just that it is random.
KEMs do have one disadvantage over asymmetric encryption schemes: You can no longer encrypt the same message to multiple recipients, since each encapsulate call will create a new, random shared secret. There is a way to recover this ability, through using something called an mKEM, but that would go beyond the scope of this blog post and is not directly feasible with what NIST has standardized.
This section has gone on long enough without mentioning anything actually post-quantum, so it is high time that we change that, with the introduction of ML-KEM, née Kyber, into the mix. ML-KEM is, as the name implies, a KEM, and comes in three different sizes, called 512, 768, and 1024. Funnily enough, those numbers refer to some abstract mathematical thing (the lattice rank), and never show up in the code itself, so calling them 2, 3, and 4 (the module rank) would probably have been the better choice.
| Algorithm | Public Key Size | Ciphertext Size | Speed | Security Scaling |
| RSA-2048-KEM | ~256 bytes | 256 bytes | Very fast encaps, slow decaps | subexponential* |
| ECIES-KEM (X25519) | 32 bytes | 32 bytes | fast encaps and decaps | exponential* |
| ML-KEM-768 | 1184 bytes | 1088 bytes | fast encaps and decaps | exponential |
| X-Wing | 1216 bytes | 1120 bytes | fast encaps and decaps | exponential |
Overview of different KEMs at the recommended (by me) parameter sets.
*: Unless a quantum computer is build, when it becomes polynomial
In this table, you can see an entry I haven’t mentioned so far, X-Wing. X-Wing is what is called a hybrid KEM, combining both X25519 and ML-KEM-768 into a single primitive. You can tell that by noticing that the public key and the ciphertext are just concatenated versions of the two schemes. The real magic of X-Wing happens in its key derivation function, where it combines the two shared secrets in such a way that the resulting primitive is a secure KEM as long as either X25519 or ML-KEM-768 are a secure KEM.
All in all, the extra cost of the X25519 key agreement is likely so small that you will want to go with X-Wing for most practical applications.
Security Levels
You might have noticed that I only put ML-KEM-768 in the table above, and that X-Wing does not have any parameter choice at all, only being defined for X25519 and ML-KEM-768 as constituent parts. The reason for that is a bit longer rant on how security levels are not the most useful tool to describe the security of cryptographic schemes. There are two main arguments for this: First, looking at RSA-2048, we get a security level of around 112 bits, and subexponential scaling means that we have to more than double the key size in order to double the security level. 112 bit is somewhat low, but for all we can currently predict, RSA-2048 will be broken at right around the same time as RSA-4096 will be, by a cryptographically relevant quantum computer. In other words, there isn’t really a good reason to use a larger RSA modulus, in terms of security strength.
On the other side, ML-KEM-512 is believed to have 128 bits of security, but the bounds there are quite tight and it is very possible that future improvements drop the security further. That has led to a sort of consensus among many cryptographers that it is best to use ML-KEM768 by default, with this consensus being reflected in the choices X-Wing made as well (full disclosure: I am not a X-Wing coauthor, but have been asked about my opinion on parameter choices by them).
Security and public key/ciphertext size scales mostly linear in ML-KEM’s security parameter, so ML-KEM-512 has a 800 byte/768 byte public key/ciphertext and ML-KEM-1024 has a 1568 byte public key and ciphertext. Performance scales quadratically in the security parameter, which makes using larger security levels a lot less painful than with RSA and elliptic curves, which scale worse than cubical. To finish this section on security levels, while there is mostly a consensus around ML-KEM-768 being the recommended choice, there is one important outlier here, with the NSA recommending ML-KEM-1024 for all clearance levels.
Implicit Rejection and Misbinding
There is a weird property that ML-KEM has, that warrants its own subsection, implicit rejection. This deals with the question of what happens when an adversary manipulates a ciphertext instead of creating a fresh one, or constructs an invalid ciphertext. What is weird here is that ML-KEM’s decapsulation method will detect such a manipulation, but instead of failing, it will return a “shared” secret that is only known to a party with access to the private key. While this behavior seems weird at first, it mimics what RSA-KEM and ECIES-KEM do involuntarily in this case as well, but it is a strange behavior that has some even stranger side effects, and really only exists because of the specific metrics that the NIST competition incentivized, and not because it is necessarily the best choice in practice. One of the even stranger side effects is on ML-KEM’s binding properties, a property related to the invisible salamander properties some AEADs exhibit. Those were first discussed in a paper with the excellent title “Keeping up with the KEMs”, and I also had to chime in on the topic, and, trying to keep with the pun, wrote “Unbindable Kemmy Schmidt”. Compared to invisible salamanders, these attacks are far harder to imagine being exploitable in a real world setting, but there is an easy and FIPS compliant way to deal with the more powerful attack, by using the 64 byte seed as the private key instead of the expanded version that ML-KEM also defines. This has led to libraries like BoringSSL making the seed the standard representation of the private key on the wire, which has the side benefit of being very small.
More on Performance
To conclude this section on KEMs, a few more words on performance. I already mentioned that performance scales quadratically in the security parameter, but, another thing worth noting is what is needed to make ML-KEM fast in practice. There are two main parts to ML-KEM that influence its performance: Decompressing a matrix using SHAKE (a SHA3 variant) and performing matrix-vector multiplication on this matrix. Different from both RSA and ECC, this is not done modulo a particularly large prime, with the prime used, 3329, comfortably fitting into a 16 bit integer, with 4 bits left to spare. Together, this means that to accelerate performance, you need to accelerate SHA3 and/or use vector instruction sets. If you want to get even more performance, the remaining somewhat costly part of ML-KEM is a NTT, i.e. a Fast Fourier Transform, so a vector unit that can speed those up will likely also help ML-KEM.
Another important note on performance is the caching behavior of ML-KEM. As mentioned, one of the most expensive steps in ML-KEM is the expansion of a seed into a matrix. This matrix is part of the public key, and does not change between encapsulate or decapsulate calls as long as the same public key is used, so it can be cached if memory is plentiful. On the wire, the matrix here is only 32 bytes in size (and the reason why the public key does not scale perfectly linearly), expanded it becomes 
The performance of X-Wing is pretty much what you get when you have to run both X25519 and ML-KEM together. You can technically parallelize these calls right up to the key derivation step, but that will likely just result in race conditions and not have a major impact on performance, since both are decently fast, as far as asymmetric cryptography is concerned.
Digital Signature Schemes
With the detailed discussion of KEMs out of the way, we can get to digital signatures. On the primitive side, those are the same digital signatures you are probably familiar with, using the same interface as ECDSA or RSA signatures. For completeness sake, here is the interface:
// Non-deterministic method
pair<PrivateKey, PublicKey> GenerateKeyPair();
// Potentially non-deterministic method
Signature Sign(PrivateKey sk, ByteString msg);
// deterministic method
bool Verify(PublicKey pk, ByteString msg, Signature sig);API for Digital Signatures, in some weird pseudo C++
This makes the signature schemes NIST standardized far more of a drop-in replacement for classical schemes. Here they are in a comparison table:
| Algorithm | Public Key Size | Signature Size | Speed | Security Scaling |
| RSA-2048-PKCS1 | ~256 bytes | 256 bytes | Slow signing Very fast verifying | subexponential* |
| ECDSA | 32 bytes | 64 bytes | Fast signing and verifying | exponential* |
| ML-DSA-65 | 1952 bytes | 3309 bytes | Fast signing and verifying | exponential |
| SLH-DSA-SHA2-128s | 32 bytes | 7856 bytes | Slow signing, decent verifying | exponential |
Overview of different Digital Signature Schemes at the recommended (by me) parameter sets.
*: Unless a quantum computer is build, when it becomes polynomial
Again, we can see that the PQC algorithms, in particularly ML-DSA are comparable in speed, but have far larger overhead. At first, SLH-DSA’s public key size seems like an exception, but if you want a small signature public key, you can always just hash the public key and attach the unhashed public key to the signature, in which case ML-DSA would take the lead again. The signature size problem is in fact so large that it poses a significant problem for TLS, necessitating the blog post I’m procrastinating on.
ML-DSA again comes in three different flavors, ML-DSA-44, ML-DSA-65, and ML-DSA-87. The security parameter here is not a two digit number, but two single digit integers written without a space in between them. Since confusing lay people seems to have been an explicit security goal here, the authors went with the parameter that actually shows up in the code (aka the module ranks), instead of ML-KEM’s theoretical only lattice rank, so (4, 4), (6, 5), and (8, 7) correspond to ML-KEM’s 2, 3, and 4.
In order to compete on the confusion metric, SLH-DSA comes in way too many flavors. It mainly requires a hash function, with NIST allowing both SHA2 and SHA3/SHAKE as possible choices, in three different sizes each. There are also variants for faster signing at the cost of even larger signatures, and the prehashing thing they added for some reason which I’ll rant about below, totaling 24 different versions of SLH-DSA, of which maybe 2 are useful in practice as far as I can see.
Security Discussion
I again made the choice of parameters in the table for you, but in this case ML-DSA-44 is not quite as tightly scraping by the security level, making it somewhat more acceptable. The overhead again scales linearly in the security parameter, with ML-DSA-44 having 1312 byte public keys and 2420 byte signatures, and ML-DSA-87 having 2592 byte public keys and 4627 byte signatures. The NSA again requires ML-DSA-87 for all applications (and sadly dislikes SLH-DSA).
SLH-DSA’s security deserves some special discussion. You might have noticed that I recommended the smallest parameter choice here, and that is not just due to it otherwise being pretty much intolerable, with 16 KB to 50 KB signatures at the higher/faster settings. SLH-DSA has a proof that reduces its security to that of the underlying hash function, that is as long as the hash function is secure, SLH-DSA based on the hash function is secure. Since hash functions by now have been very well understood, we can be more aggressive with the parameter choice and use the same 128 bit security level we also use for our current elliptic curve based cryptography.
This fact also makes SLH-DSA uniquely suited as a replacement for use cases where the public key cannot be rotated easily, in particular signatures used to verify the integrity of firmware updates for secure boot. It also helps that all you need to implement SLH-DSA is an implementation of the hash function (which you then proceed to call an ungodly amount of times), which makes SLH-DSA uniquely well suited for hardware applications.
For all other use cases, ML-DSA wins on both overhead and performance, so anything that can be updated to account for the unlikely event of potential mathematical breakthroughs is probably better served using ML-DSA.
Performance Discussion
As mentioned, SLH-DSA uses hash function calls. A lot of hash function calls. Accelerating those is probably a good idea if you want to use SLH-DSA.
SLH-DSA has another curious security property: Its security depends on how many signatures have been created with the scheme. The NIST parameter sets are secure as long as “only” 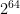
With this, we can move on to discuss ML-DSA. The algorithm used there is closely related to the one used in ML-KEM, so the discussion there applies here as well, SHA3, vector instruction sets, and NTT being the biggest things to accelerate. The prime used here, 8,380,417, is slightly larger, but still comfortably fits in a 32 bit integer. This larger prime also makes the cached matrix a lot larger, 
Another quirk of ML-DSA, important for hardware implementations in particular, is that the raw signing procedure is not always successful, and has to be repeated until a signature can be obtained. This means the implementation technically requires a while loop, although one can alternatively also just calculate an upper bound at which the probability of not being able to find a signature becomes vanishingly small, which NIST has done and added as an allowed alternative to the standard.
Randomized Signing
Both ML-DSA and SLH-DSA can create signatures in a randomized or a deterministic fashion. Classically, this has been a discussion in the case of ECDSA, with the argument in favor of deterministic signatures being that a signer with insufficient entropy can still produce secure signatures. The argument in favor of randomized signatures is that they are more robust against certain type of fault injection attacks, but all in all, neither argument has been particularly convincing to me. Not having entropy available basically destroys all ability to do secure cryptography, so salvaging one part of one primitive is rarely going to make a difference. On the other hand, fault attacks are essentially asking whether an entirely different algorithm that just happens to share some instructions with the original is secure, which usually isn’t the case.
Thankfully, in the case of PQ signatures, we do not have to choose. The randomized variant in both cases devolves seamlessly into the deterministic variant if no entropy is available, so always using the randomized option is the more secure choice, and has no performance implications. If one knows that no entropy is available, the deterministic algorithm can be used to be more honest about the situation, but really randomized should be the default choice.
There are some exotic protocols that require signatures to be deterministic, so use the deterministic version in those cases as well, but you are unlikely to run into those by accident.
Hybrid Signatures
Similar to KEMs, signatures can also be hybridized. Where KEMs needed some borderline magical key derivation functions to achieve the “secure if either is secure” property, for signatures that can be done with the somewhat simpler “logical and” between the two verification calls. There are some pending RFC drafts for this as well, but the necessity here is not as pressing. On the ML-DSA side, if you are able to change your public key and given that there is no secrets to leak, just forgeries to avoid, we can switch the PQ scheme if we are aware of any weaknesses. For SLH-DSA, this gets even stronger, since all signature algorithms, including all classical signature algorithms, are only secure if the hash function used in the scheme is secure, so combining SLH-DSA with another scheme is not really useful.
That being said, a classical ECDSA/EdDSA or even RSA signature is so tiny in comparison that adding it to the ML-DSA signature is not going to change things much, so you might as well, it does protect you against mathematical advances that happen outside of the public view.
Prehashing, a Rant
I very briefly mentioned prehashing above, as a reason why SLH-DSA has another factor of 2 more variants. Prehashing technically also exists for ML-DSA, where it makes even less sense, but I’m getting ahead of myself.
As you might be able to tell, I don’t have the highest opinion of prehashing, but let’s start at the beginning:
In the case of RSA-PKCS1, RSA-PSS, and ECDSA, the very first operation the algorithm does is to hash the message down to a more manageable size. This can be used by HSMs and remote signing oracle by computing the hash outside of the HSM/locally and only transmitting the hash of the message to be signed. However, doing this has some implications for some properties beyond forgability resistance, such as the public key recovery I discussed in the previous blog post, and more importantly something called non-resignability, which NIST encouraged schemes to achieve. This led to both ML-DSA and SLH-DSA departing from the simple hash as a first step paradigm, and instead mixing the message into the scheme in a more complicated fashion. In the case of ML-DSA, this “more complicated” fashion is just a hash of the public key together with the message, which still can be computed outside of the HSM/remote signing oracle, but in the case of SLH-DSA even that is not possible.
FIPS 204 explicitly allows for ML-DSA prehashing the message by computing this first hash in a different place, and in my opinion that is the way prehashing should be accomplished there.
For SLH-DSA, this isn’t possible. In my opinion, that simply means that it should not be done, and that instead any protocol (where a protocol is not necessarily interactive) that requires the message size to be small should specify the hashing of the message on the protocol level, instead of trying to make a primitive, which does intentionally not support such an operation, to support it anyways. Unfortunately, this is exactly what NIST has done, technically for both SLH-DSA and ML-DSA, with ML-DSA also allowing for the actual prehashing as described above. What this means is that there are two versions for each signature scheme and parameter set, obtained by either prefixing 0x00 to the message or prefixing 0x01, a hash OID, and the hash of the message before feeding the so manipulated input into the underlying signature scheme, thus essentially defining a protocol on the primitive level. You should not use the same key for both prehashed and not-prehashed messages, mostly due to the primitive otherwise not being a well-defined signature scheme anymore (i.e. the API defined above would have to change to allow another input when signing/verifying), and if you fix whether a key is always used prehashed or always used non-prehashed, you just defined a protocol, and adding this step to the primitive was unnecessary.
Anyways, it’s a thing the standard allows for, but ideally we should all just collectively ignore that this option exists and always use the non-prehashed variants (with exception of the true prehashing of ML-DSA), and just define our protocols to correctly work with our use cases.