In Part I, we looked at the problem we want attackers of UOV to solve. In Part II we had plenty of oil and vinegar, but did not really discussed the whole unbalanced part of the scheme. So in this third part of this three part series, I will discuss why we are using Unbalanced Oil and Vinegar in particular, and discuss the Kipnis–Shamir attack on the original Oil and Vinegar scheme.
The paper that presented this attack is formulated in the language of matrices, but in my opinion, and showing my biases as a algebraic geometer, one can’t fully understand the problem when in this language, and I will instead present it in the language of bilinear forms, that I have build over the last two blog posts. Using bilinear forms is useful, since it allows us to present things without having to chose an explicit basis, which means that we do not really have to distinguish between the public and the private key all that much.
Preliminaries
Most of this section is a mini course in linear algebra and in particular bilinear forms and dual vector spaces. I will try to also formulate the attack purely in terms of matrices, so if this is going too far for you, you might still follow along with the attack, but as mentioned, using the language of bilinear forms in my opinion gives a deeper understanding.
First, as a quick refresher, as discussed in Part II, a UOV public key is a set of 




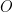
We also need some additional vocabulary to talk about bilinear forms. Bilinear forms in positive characteristic behave somewhat weirdly sometimes, so it makes sense to prove stuff from scratch anyways.
First, we need to discuss non-degenerate bilinear forms. A bilinear form is called non-degenerate, if, for all vectors 


The reason we care about non-degenerate bilinear forms is because they allow us, on a finite dimensional vector space at least, to “transpose” vectors, i.e. turn column vectors into row vectors. If you know quantum physics, what a non-degenerate bilinear form does is turn a ket vector into a bra vector. If you don’t know quantum physics, don’t worry about it, those are just terms the quantum physicists invented because they didn’t know enough about bilinear forms and dual vector spaces.
To understand dual vector spaces, all you need to know here is that linear forms, i.e. linear functions that output a single scalar, themselves also form a vector space over the same field, since you can add linear forms and multiply them with scalars. Conceptually, these are literally just row vectors, as mentioned above, since those can be multiplied with column vectors to give elements of the base field, i.e. row vectors define all the linear forms that exists (for a finite dimensional vector space. Infinite dimensional vector spaces are very, very different, and to take back my comment on quantum physicists a bit, those are what quantum physics deals with, but still, understanding dual vector spaces would make their field a whole lot more approachable). We write 
To tie this to our bilinear forms, the important thing a bilinear form allows you to do is to “curry”, or partially evaluate it, that is given a bilinear form 
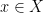

And for non-degenerate forms, doing this partial evaluation gives you an extra property, namely that, if 




Next, we need to talk about orthogonality. This term really only makes geometric sense in characteristic 0, but we can still use it algebraically: Two vectors 





While this is somewhat obviously nonsensically in a geometric way, we can rescue at least one property of perpendicularity into positive characteristic, and that is the dimension of the orthogonal space:
For a non-degenerate bilinear form 








The Attack
With all of this out of the way, we can now look at the attack itself. So in the following, we have 






The main idea behind the Kipnis–Shamir attack is that bilinear forms are hard, but linear functions are easy, and that for two non-degenerate bilinear forms 




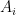



So far, so unremarkable. You have a bunch of bilinear forms, you can define this linear function. But now, we can ask what 









But for a linear function, restricting to a subvectorspace as an endomorphism is the same as saying that this subvectorspace is a product of eigenspaces. And we can compute the eigenspaces of a linear function. By itself that is only moderately helpful, since we don’t know which eigenspaces of 
To put it together, the attack algorithm works as follows:
- Discard all singular matrices, as they correspond to degenerate bilinear forms.
- Compute
for enough
.
- Take an arbitrary linear combination of the computed matrices
- Compute the characteristic polynomial of
and factorize it.
- Due to the common eigenspace, the characteristic polynomial will always have a factor of degree m. But it might have more factors. If there are more factors, discard and try a new linear combination. If you do not find such a matrix and factorization, continue at step 7.
- By Cayley–Hamilton, the kernel of factor of the characteristic polynomial, evaluated at the matrix, is the eigenspace of the matrix. Since our matrix has a characteristic polynomial which only has two factors, one of the two eigenspaces is the oil space, which we can quickly verify.
- Read the paper for why finding such a characteristic polynomial is very likely, so you never reach this step.

A geometric interpretation
I have to admit, when I first read about this attack, I found it extremely devastating. A polynomial time attack on one member of a family of schemes is a very frightening thing to see, and while the attack clearly requires n = 2m to work (Otherwise the whole eigenspace argument falls apart), at least I would like to see some form of an argument why n > 2m somehow is not just mitigating this specific attack, but also fundamentally has a structure that is somehow more complex than the balanced case is.
I think I have found such an argument, but as a fair word of warning, what follows will be some take no prisoners, deep, deep end of the algebraic geometric pool. Well the shallow end of the deep end, but you get my drift. I will try to keep the argument understandable for more general audiences, but you’ll have to take a bunch of things I say at face value. The whole argument is part of a deeper investigation I did on UOV, but that should properly be a different blog post, or maybe a CFAIL paper or something like that.
With the disclaimers out of the way, here we go:
If an algebraic geometer is given m polynomials, even if they are just quadratic forms, our basic instincts kicks in, and we study the geometric object obtained by setting all these polynomials to zero. I will call this the oil-and-vinegar variety, i.e. ![S = \text{Spec} K[X]/((X, X)_i)](https://s0.wp.com/latex.php?latex=S+%3D+%5Ctext%7BSpec%7D+K%5BX%5D%2F%28%28X%2C+X%29_i%29&bg=ffffff&fg=000&s=0&c=20201002)
animalisticgeometric urges in check and not look at 


The other thing to notice is that 
So in the balanced case, where n = 2m,

Artist’s impression of the OV-variety for m = 1, n = 2. You can see the linear subspace as irreducible component. Note that this is a polynomial of degree 3, so it is not actually a valid OV-variety, but it would look boring otherwise.
In the unbalanced case however, n > 2m, so 

Plot of a m = 1, n = 3 OV-variety. There are plenty of linear subspaces to chose from (which would not usually be the case), but they are all located on a single irreducible component which is decisively non-linear. It’s still not the greatest picture, since the plotting software limits me to three dimensions only.